
Scaling robotics datasets with video encoding
- +35



Over the past few years, text and image-based models have seen dramatic performance improvements, primarily due to scaling up model weights and dataset sizes. While the internet provides an extensive database of text and images for LLMs and image generation models, robotics lacks such a vast and diverse qualitative data source and efficient data formats. Despite efforts like Open X , we are still far from achieving the scale and diversity seen with Large Language Models. Additionally, we lack the necessary tools for this endeavor, such as dataset formats that are lightweight, fast to load from, easy to share and visualize online. This gap is what 🤗 LeRobot aims to address.
What's a dataset in robotics?
In their general form — at least the one we are interested in within an end-to-end learning framework — robotics datasets typically come in two modalities: the visual modality and the robot's proprioception / goal positions modality (state/action vectors). Here's what this can look like in practice:
Until now, the best way to store visual modality was PNG for individual frames. This is very redundant as there's a lot of repetition among the frames. Practitioners did not use videos because the loading times could be orders of magnitude above. These datasets are usually released in various formats from academic papers (hdf5, zarr, pickle, tar, zip...). These days, modern video codecs can achieve impressive compression ratios — meaning the size of the encoded video compared to the original uncompressed frames — while still preserving excellent quality. This means that with a compression ratio of 1:20, or 5% for instance (which is easily achievable), you get from a 20GB dataset down to a single GB of data. Because of this, we decided to use video encoding to store the visual modalities of our datasets.
Contribution
We propose a LeRobotDataset format that is simple, lightweight, easy to share (with native integration to the hub) and easy to visualize. Our datasets are on average 14% the size their original version (reaching up to 0.2% in the best case) while preserving full training capabilities on them by maintaining a very good level of quality. Additionally, we observed decoding times of video frames to follow this pattern, depending on resolution:
- In the nominal case where we're decoding a single frame, our loading time is comparable to that of loading the frame from a compressed image (png).
- In the advantageous case where we're decoding multiple successive frames, our loading time is 25%-50% that of loading those frames from compressed images.
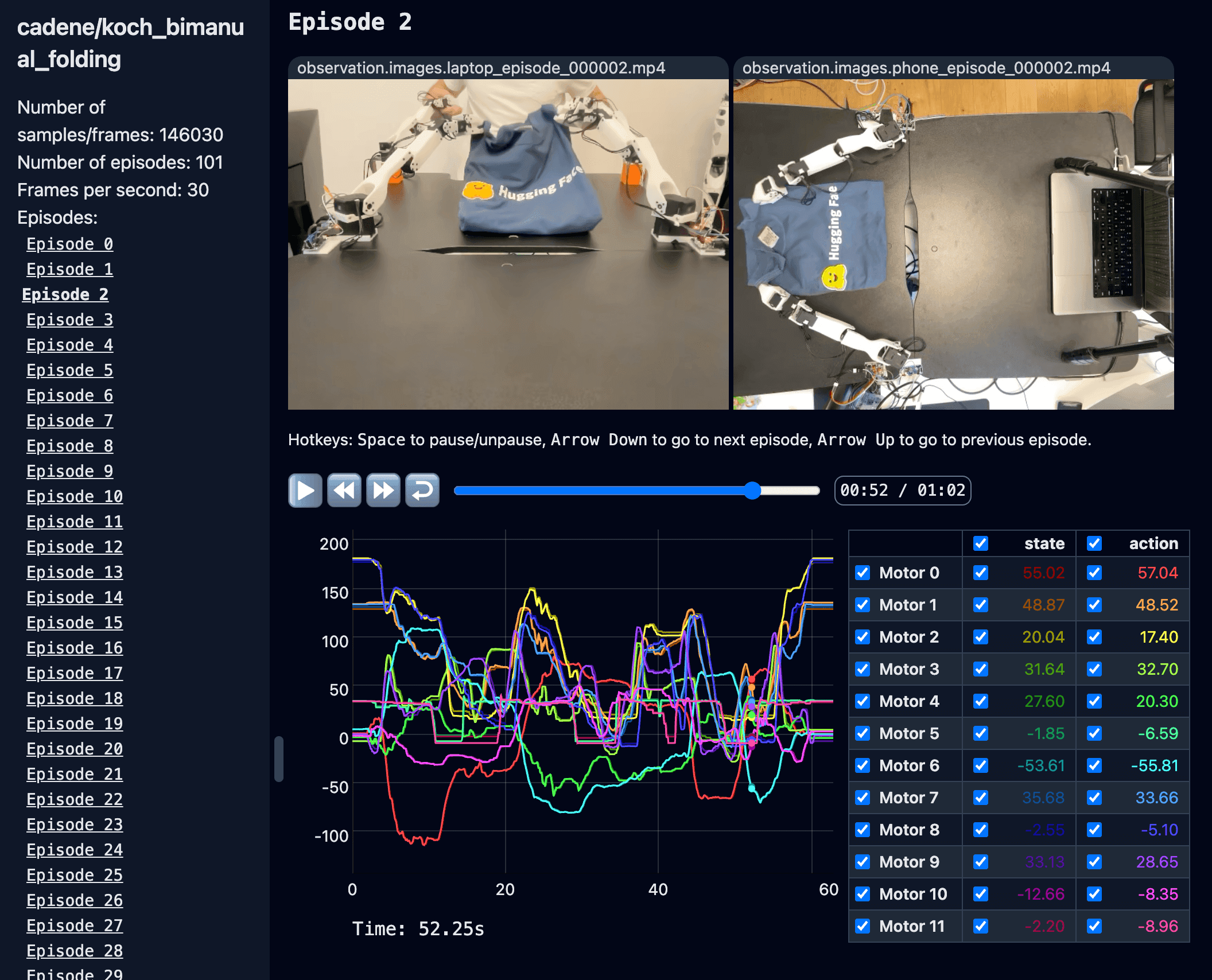
On top of this, we're building tools to easily understand and browse these datasets. You can explore a few examples yourself in the following Spaces using our visualization tool (click the images):
aliberts/koch_tutorial

cadene/koch_bimanual_folding
But what is a codec? And what is video encoding & decoding actually doing?
At its core, video encoding reduces the size of videos by using mainly 2 ideas:
- Spatial Compression: This is the same principle used in a compressed image like JPEG or PNG. Spatial compression uses the self-similarities of an image to reduce its size. For instance, a single frame of a video showing a blue sky will have large areas of similar color. Spatial compression takes advantage of this to compress these areas without losing much in quality.
- Temporal Compression: Rather than storing each frame as is , which takes up a lot of space, temporal compression calculates the differences between each frame and keeps only those differences (which are generally much smaller) in the encoded video stream. At decoding time, each frame is reconstructed by applying those differences back. Of course, this approach requires at least one frame of reference to start computing these differences with. In practice though, we use more than one placed at regular intervals. There are several reasons for this, which are detailed in this article . These "reference frames" are called keyframes or I-frames (for Intra-coded frames).
Thanks to these 2 ideas, video encoding is able to reduce the size of videos down to something manageable. Knowing this, the encoding process roughly looks like this:
- Keyframes are determined based on user's specifications and scenes changes.
- Those keyframes are compressed spatially.
- The frames in-between are then compressed temporally as "differences" (also called P-frames or B-frames, more on these in the article linked above).
- These differences themselves are then compressed spatially.
- This compressed data from I-frames, P-frames and B-frames is encoded into a bitstream.
- That video bitstream is then packaged into a container format (MP4, MKV, AVI...) along with potentially other bitstreams (audio, subtitles) and metadata.
- At this point, additional processing may be applied to reduce any visual distortions caused by compression and to ensure the overall video quality meets desired standards.
Obviously, this is a high-level summary of what's happening and there are a lot of moving parts and configuration choices to make in this process. Logically, we wanted to evaluate the best way of doing it given our needs and constraints, so we built a benchmark to assess this according to a number of criteria.
Criteria
While size was the initial reason we decided to go with video encoding, we soon realized that there were other aspects to consider as well. Of course, decoding time is an important one for machine learning applications as we want to maximize the amount of time spent training rather than loading data. Quality needs to remains above a certain level as well so as to not degrade our policies' performances. Lastly, one less obvious but equally important aspect is the compatibility of our encoded videos in order to be easily decoded and played on the majority of media player, web browser, devices etc. Having the ability to easily and quickly visualize the content of any of our datasets was a must-have feature for us.
To summarize, these are the criteria we wanted to optimize:
- Size: Impacts storage disk space and download times.
- Decoding time: Impacts training time.
- Quality: Impacts training accuracy.
- Compatibility: Impacts the ability to easily decode the video and visualize it across devices and platforms.
Obviously, some of these criteria are in direct contradiction: you can hardly e.g. reduce the file size without degrading quality and vice versa. The goal was therefore to find the best compromise overall.
Note that because of our specific use case and our needs, some encoding settings traditionally used for media consumption don't really apply to us. A good example of that is with GOP (Group of Pictures) size. More on that in a bit.
Metrics
Given those criteria, we chose metrics accordingly.
- Size compression ratio (lower is better) : as mentioned, this is the size of the encoded video over the size of its set of original, unencoded frames.
- Load times ratio (lower is better) : this is the time it take to decode a given frame from a video over the time it takes to load that frame from an individual image.
For quality, we looked at 3 commonly used metrics:
- Average Mean Square Error (lower is better): the average mean square error between each decoded frame and its corresponding original image over all requested timestamps, and also divided by the number of pixels in the image to be comparable across different image sizes.
- Average Peak Signal to Noise Ratio (higher is better): measures the ratio between the maximum possible power of a signal and the power of corrupting noise that affects the fidelity of its representation. Higher PSNR indicates better quality.
- Average Structural Similarity Index Measure (higher is better): evaluates the perceived quality of images by comparing luminance, contrast, and structure. SSIM values range from -1 to 1, where 1 indicates perfect similarity.
Additionally, we tried various levels of encoding quality to get a sense of what these metrics translate to visually. However, video encoding is designed to appeal to the human eye by taking advantage of several principles of how the human visual perception works, tricking our brains to maintain a level of perceived quality. This might have a different impact on a neural net. Therefore, besides these metrics and a visual check, it was important for us to also validate that the encoding did not degrade our policies performance by A/B testing it.
For compatibility, we don't have a metric per se , but it basically boils down to the video codec and the pixel format. For the video codec, the three that we chose (h264, h265 and AV1) are common and don't pose an issue. However, the pixel format is important as well and we found afterwards that on most browsers for instance, yuv444p is not supported and the video can't be decoded.
Variables
Image content & size
We don't expect the same optimal settings for a dataset of images from a simulation, or from the real world in an apartment, or in a factory, or outdoor, or with lots of moving objects in the scene, etc. Similarly, loading times might not vary linearly with the image size (resolution). For these reasons, we ran this benchmark on four representative datasets:
- lerobot/pusht_image : (96 x 96 pixels) simulation with simple geometric shapes, fixed camera.
- aliberts/aloha_mobile_shrimp_image : (480 x 640 pixels) real-world indoor, moving camera.
- aliberts/paris_street : (720 x 1280 pixels) real-world outdoor, moving camera.
- aliberts/kitchen : (1080 x 1920 pixels) real-world indoor, fixed camera.
Encoding parameters
We used FFmpeg for encoding our videos. Here are the main parameters we played with:
Video Codec ( vcodec )
The codec ( co der- dec oder) is the algorithmic engine that's driving the video encoding. The codec defines a format used for encoding and decoding. Note that for a given codec, several implementations may exist. For example for AV1: libaom (official implementation), libsvtav1 (faster, encoder only), libdav1d (decoder only).
Note that the rest of the encoding parameters are interpreted differently depending on the video codec used. In other words, the same crf value used with one codec doesn't necessarily translate into the same compression level with another codec. In fact, the default value ( None ) isn't the same amongst the different video codecs. Importantly, it is also the case for many other ffmpeg arguments like g which specifies the frequency of the key frames.
Pixel Format ( pix_fmt )
Pixel format specifies both the color space (YUV, RGB, Grayscale) and, for YUV color space, the chroma subsampling which determines the way chrominance (color information) and luminance (brightness information) are actually stored in the resulting encoded bitstream. For instance, yuv420p indicates YUV color space with 4:2:0 chroma subsampling. This is the most common format for web video and standard playback. For RGB color space, this parameter specifies the number of bits per pixel (e.g. rbg24 means RGB color space with 24 bits per pixel).
Group of Pictures size ( g )
GOP (Group of Pictures) size determines how frequently keyframes are placed throughout the encoded bitstream. The lower that value is, the more frequently keyframes are placed. One key thing to understand is that when requesting a frame at a given timestamp, unless that frame happens to be a keyframe itself, the decoder will look for the last previous keyframe before that timestamp and will need to decode each subsequent frame up to the requested timestamp. This means that increasing GOP size will increase the average decoding time of a frame as fewer keyframes are available to start from. For a typical online content such as a video on Youtube or a movie on Netflix, a keyframe placed every 2 to 4 seconds of the video — 2s corresponding to a GOP size of 48 for a 24 fps video — will generally translate to a smooth viewer experience as this makes loading time acceptable for that use case (depending on hardware). For training a policy however, we need access to any frame as fast as possible meaning that we'll probably need a much lower value of GOP.
Constant Rate Factor ( crf )
The constant rate factor represent the amount of lossy compression applied. A value of 0 means that no information is lost while a high value (around 50-60 depending on the codec used) is very lossy. Using this parameter rather than specifying a target bitrate is preferable since it allows to aim for a constant visual quality level with a potentially variable bitrate rather than the opposite.









This table summarizes the different values we tried for our study:
Decoding parameters
Decoder
We tested two video decoding backends from torchvision:
- pyav (default)
- video_reader
Timestamps scenarios
Given the way video decoding works, once a keyframe has been loaded, the decoding of subsequent frames is fast. This of course is affected by the -g parameter during encoding, which specifies the frequency of the keyframes. Given our typical use cases in robotics policies which might request a few timestamps in different random places, we want to replicate these use cases with the following scenarios:
- 1_frame : 1 frame,
- 2_frames : 2 consecutive frames (e.g. [t, t + 1 / fps] ),
- 6_frames : 6 consecutive frames (e.g. [t + i / fps for i in range(6)] )
Note that this differs significantly from a typical use case like watching a movie, in which every frame is loaded sequentially from the beginning to the end and it's acceptable to have big values for -g .
Additionally, because some policies might request single timestamps that are a few frames apart, we also have the following scenario:
- 2_frames_4_space : 2 frames with 4 consecutive frames of spacing in between (e.g [t, t + 5 / fps] ),
However, due to how video decoding is implemented with pyav , we don't have access to an accurate seek so in practice this scenario is essentially the same as 6_frames since all 6 frames between t and t + 5 / fps will be decoded.
Results
After running this study, we switched to a different encoding from v1.6 on.
We managed to gain more quality thanks to AV1 encoding while using the more compatible yuv420p pixel format.
Sizes
We achieved an average compression ratio of about 14% across the total dataset sizes. Most of our datasets are reduced to under 40% of their original size, with some being less than 1%. These variations can be attributed to the diverse formats from which these datasets originate. Datasets with the highest size reductions often contain uncompressed images, allowing the encoder’s temporal and spatial compression to drastically reduce their sizes. On the other hand, datasets where images were already stored using a form of spatial compression (such as JPEG or PNG) have experienced less reduction in size. Other factors, such as image resolution, also affect the effectiveness of video compression.
* These datasets contain depth maps which were not included in our format.
Loading times
Thanks to video encoding, our loading times scale much better with the resolution. This is especially true in advantageous scenarios where we decode multiple successive frames.



Summary
The full results of our study are available in this spreadsheet . The tables below show the averaged results for g=2 and crf=30 , using backend=pyav and in all timestamps-modes ( 1_frame , 2_frames , 6_frames ).
Policies
We validated that this new format did not impact performance on trained policies by training some of them on our format. The performances of those policies were on par with those trained on the image versions.


Policies have also been trained and evaluated on AV1-encoded datasets and compared against our previous reference (h264):
- Diffusion on pusht: h264-encoded run
- AV1-encoded run
- h264-encoded run
- AV1-encoded run
- h264-encoded run
- AV1-encoded run
Future work
Video encoding/decoding is a vast and complex subject, and we're only scratching the surface here. Here are some of the things we left over in this experiment:
For the encoding, additional encoding parameters exist that are not included in this benchmark. In particular:
- -preset which allows for selecting encoding presets. This represents a collection of options that will provide a certain encoding speed to compression ratio. By leaving this parameter unspecified, it is considered to be medium for libx264 and libx265 and 8 for libsvtav1.
- -tune which allows to optimize the encoding for certain aspects (e.g. film quality, live, etc.). In particular, a fast decode option is available to optimise the encoded bit stream for faster decoding.
- two-pass encoding would also be interesting to look at as it increases quality, although it is likely to increase encoding time significantly. Note that since we are primarily interested in decoding performance (as encoding is only done once before uploading a dataset), we did not measure encoding times nor have any metrics regarding encoding. Using a 1-pass encoding did not pose any issue and it didn't take a significant amount of time during this benchmark (with the condition of using libsvtav1 instead of libaom for AV1 encoding).
The more detailed and comprehensive list of these parameters and others is available on the codecs documentations:
- h264: https://trac.ffmpeg.org/wiki/Encode/H.264
- h265: https://trac.ffmpeg.org/wiki/Encode/H.265
- AV1: https://trac.ffmpeg.org/wiki/Encode/AV1
Similarly on the decoding side, other decoders exist but are not implemented in our current benchmark. To name a few:
- torchcodec
- torchaudio
- ffmpegio
- decord
- nvc
Finally, we did not look into video encoding with depth maps. Although we did port datasets that include depth maps images, we are not using that modality for now.
More Articles from our Blog
`LeRobotDataset:v3.0`: Bringing large-scale datasets to `lerobot`
- +7
TimeScope: How Long Can Your Video Large Multimodal Model Go?
Community
· Sign up or log in to comment
- +29