
NVIDIA Releases 6 Million Multi-Lingual Reasoning Dataset
- +12



Authors: Dhruv Nathawani, Shuoyang Ding US, Vitaly Lavrukhin US, Jane Polak Scowcroft US, Oleksii Kuchaiev US
NVIDIA continues releasing permissive datasets in support of the open ecosystem with 6 Million Multilingual Reasoning Dataset .
Continuing the success of the recent Nemotron Post-Training Dataset v1 release used in Llama Nemotron Super model , and our Llama Nemotron Post-Training Dataset release earlier this year, we’re excited to release the reasoning dataset translated into five target languages: French, Spanish, German, Italian, and Japanese.
The newly released NVIDIA Nemotron Nano 2 9B brings these capabilities to the edge with leading accuracy and efficiency with a hybrid Transformer–Mamba architecture and a configurable thinking budget—so you can dial accuracy, throughput, and cost to match your real‑world needs.
Model Highlights (TL;DR)
- Model size : 9B parameters
- Architecture : Hybrid Transformer–Mamba (Mamba‑2 + a small number of attention layers) for higher throughput at similar accuracy to Transformer‑only peers
- Throughput : Up to 6× higher token generation than other leading models in its size class
- Cost : Thinking budget lets you control how many “thinking” tokens are used—saving up to 60% lower reasoning costs
- Target : Agents for customer service, support chatbots, analytics copilots, and edge/RTX deployments
- Availability : The model weights are available on Hugging Face, you can try the endpoint on build.nvidia.com, and the model will be available as NVIDIA NIM for high throughput and low latency
- License : nvidia-open-model-license
The release represents a significant step forward in our continued commitment to openness and transparency in model development and improvement. By releasing training data, in addition to the training tools and final model weights, NVIDIA supports continued improvement of open‑weight models.
What’s in the dataset and how we built it
At a high level, the Nemotron Post-Training Dataset V2 takes our previously released English reasoning data and translates them into five target languages (French, German, Italian, Japanese, Spanish). To best take advantage of English knowledge instilled during pre‑training, we translate the user prompt and model response while preserving the original English reasoning chain.
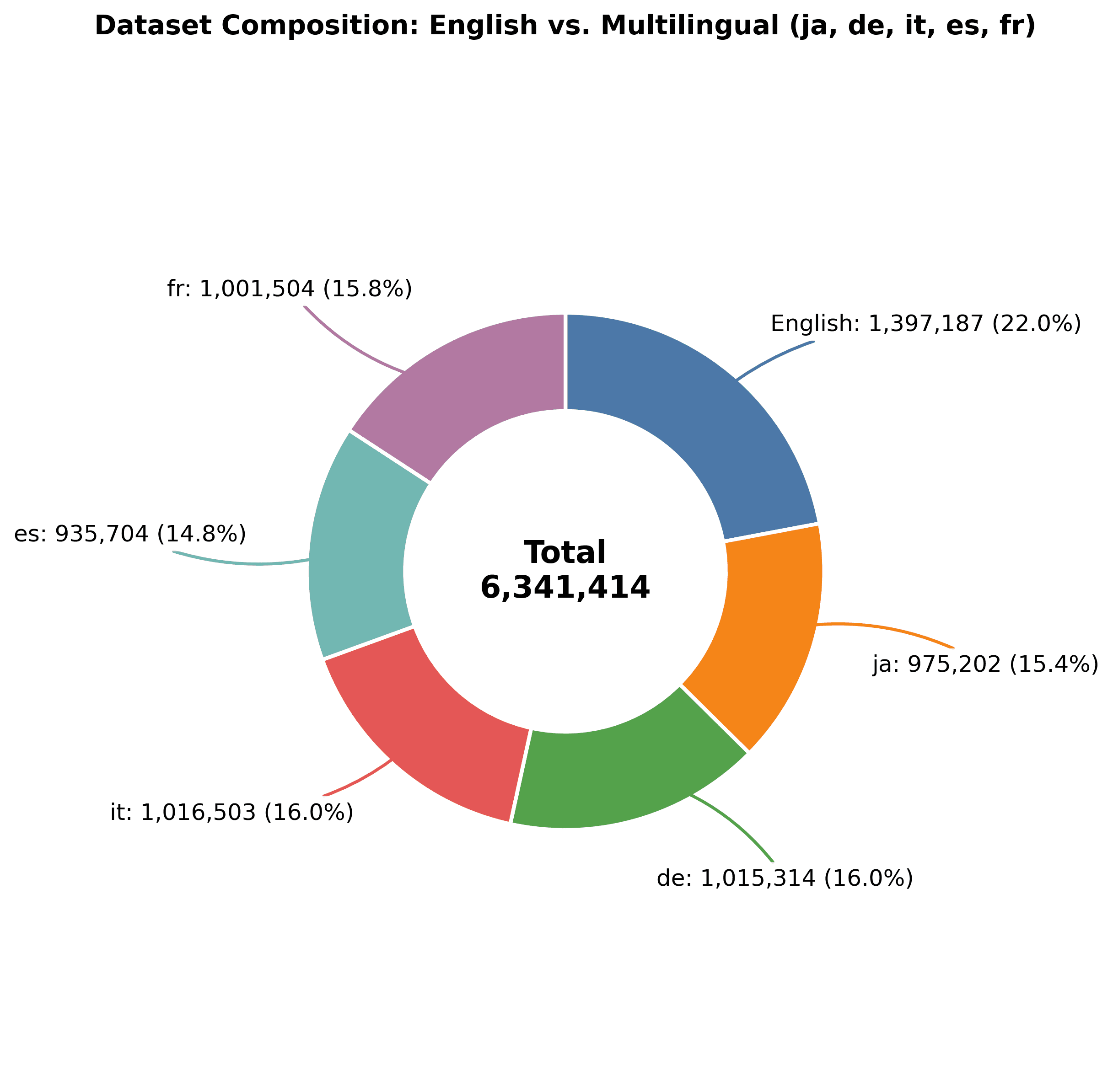
According to results from the WMT 2024 general translation shared task, LLMs are achieving state‑of‑the‑art results for machine translation tasks. However, for synthetic generation of post‑training data, our preliminary studies have shown that:
- LLMs are more prone to hallucinations when translating SFT datasets compared to translating common machine translation test sets (e.g., FLORES).
- The translation quality and hallucination rate of open‑source LLMs deteriorate significantly as input length increases.
Hence, we incorporate several mechanisms to maintain high translation quality and easy hallucination detection. To summarize:
- We break down sentences by newline and translate line‑by‑line. If a line is non‑translatable (e.g., only tabs) or is part of a code block, it won’t be translated.
- We enforce a specific format (“Wrap the translated text in brackets 〘〙”) and use this special matching bracket to extract translations. Other examples are discarded (see Table 1).
- We run fastText language ID on the translation of prompt inputs to filter out off‑target data points. We discarded another 55,567 examples (another 1.1% of all multilingual examples).
Table 1: Ratio of discarded data (measured by bytes) by enforcing output format
After benchmarking, we selected Qwen2.5-32B-Instruct-AWQ (for German) and Qwen2.5-14B-Instruct (for others) to conduct the translation. The considerations for selecting these models include:
- Robust translation quality
- Can fit onto a single A100 GPU for inference
- Wide domain coverage in training data
- Open license (Apache 2.0)
How to use it
from datasets import load_dataset
ds = load_dataset("nvidia/Nemotron-Post-Training-Dataset-v2")👉 Explore the dataset here: Hugging Face dataset page
Models mentioned in this article 1
Datasets mentioned in this article 3
More from this author
Introducing NVIDIA Nemotron 3 Nano Omni: Long-Context Multimodal Intelligence for Documents, Audio and Video Agents
Adaptive Ultrasound Imaging with Physics-Informed NV-Raw2Insights-US AI
Community
· Sign up or log in to comment
- +6