
KV Cache from scratch in nanoVLM
- +113





TL;DR
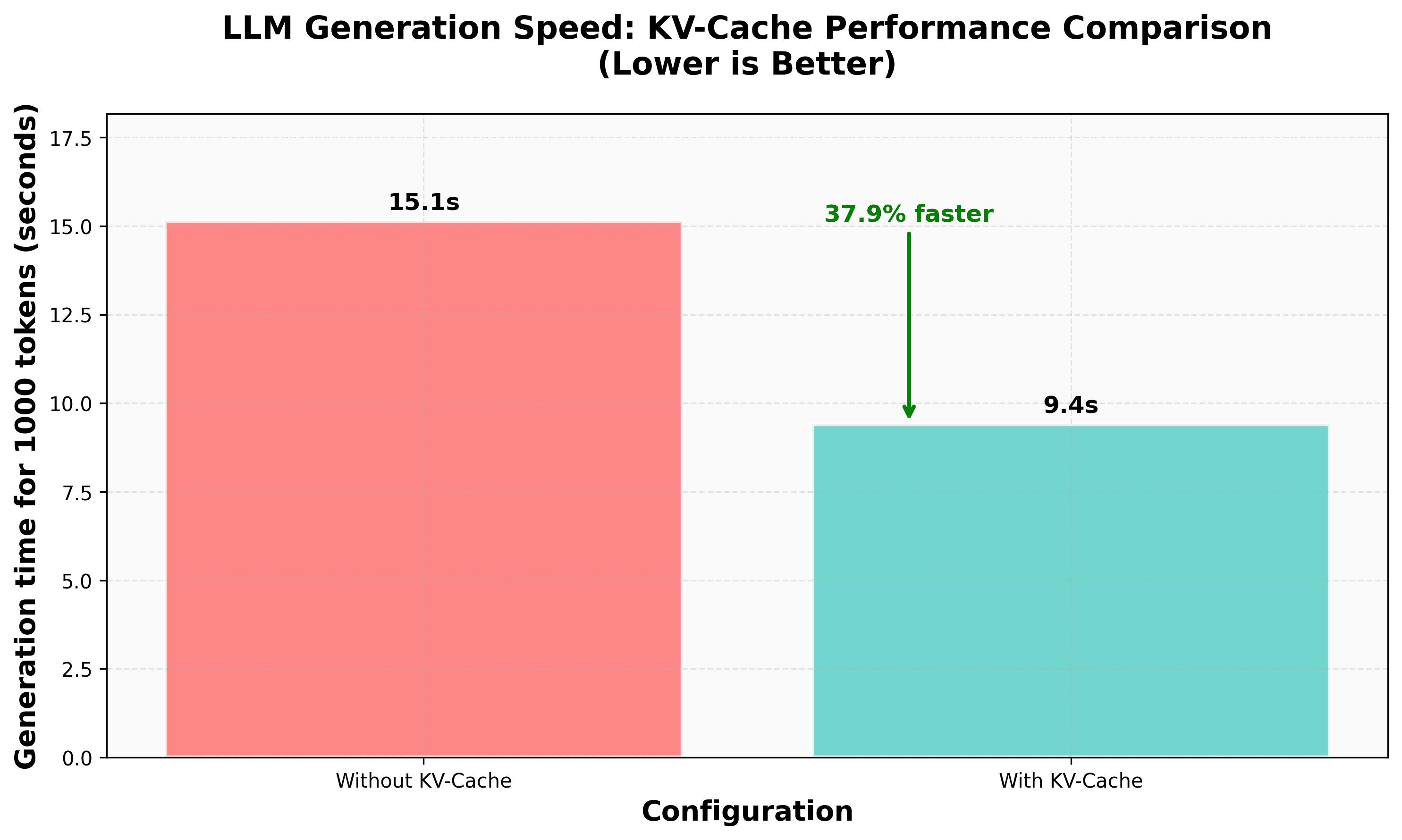
We have implemented KV Caching from scratch in our nanoVLM repository (a small codebase to train your own Vision Language Model with pure PyTorch). This gave us a 38% speedup in generation. In this blog post we cover KV Caching and all our experiences while implementing it. The lessons learnt are general and can be applied to all autoregressive language model generations. Implementing from scratch on a small codebase is a great learning experience, come along for the ride!
Introduction
Autoregressive language models generate text by sampling one token at a time . During inference, the model processes a given input sequence, predicts the next token, appends it to the sequence, and repeats this process until some stopping criterion:
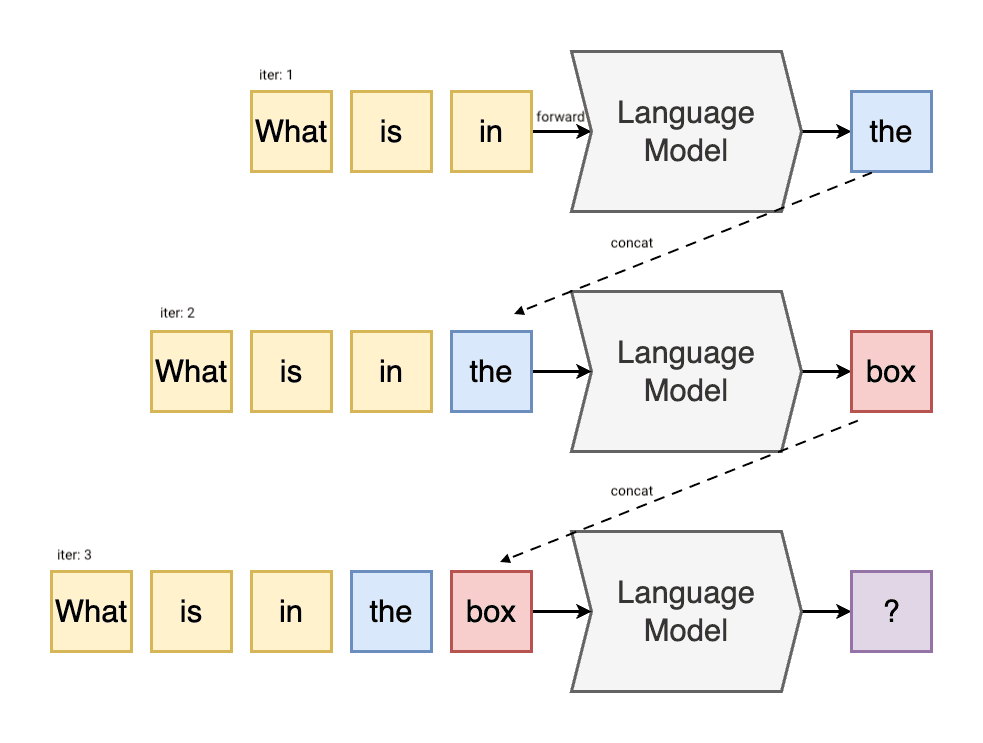
This step-by-step generation is inherently sequential:
- To generate token t i + 1 t_{i+1} t i + 1 , the model must consider the entire sequence from t 0 t_0 t 0 to t i t_i t i . From the first instance in the above example t i + 1 t_{i+1} t i + 1 would be the , while all the previous tokens t 0 t_0 t 0 to t i t_i t i would be [What, is, in] .
- Although transformers are internally parallel, each new prediction requires a full forward pass through all transformer layers, which incurs a quadratic memory/compute in terms of the sequence length.
This repetition also leads to computational redundancy . In this post, we explore KV Caching , an optimisation technique that mitigates this inefficiency.
Table of contents:
- Revisiting the Transformer Architecture
- Where Redundancy Creeps In
- How KV Caching Fixes It
- KV Caching in nanoVLM: From Theory to Practice
- Summary: Why KV Caching Matters
Revisiting the Transformer Architecture
Before diving into caching, let’s revisit how attention operates in transformer models. A Transformer language model consists of stacked layers, each composed of:
- Multi-head self-attention
- Feed-forward network (MLP)
- Residual connections and layer normalisation
To understand where KV Caching helps , we focus on the self-attention mechanism, specifically within a single attention head.
Let’s walk through a simple PyTorch implementation to visualise the key computations.
import torch
input_seq_length = 5
dim_model = 10
input_ids_emb = torch.randn(input_seq_length, dim_model)
W_q = torch.randn(dim_model, dim_model)
W_k = torch.randn(dim_model, dim_model)
W_v = torch.randn(dim_model, dim_model)
Q = input_ids_emb @ W_q
K = input_ids_emb @ W_k
V = input_ids_emb @ W_vSelf-Attention Computation
For a sequence of T T T input embeddings represented as X ∈ R T × D X \in \mathbb{R}^{T \times D} X ∈ R T × D , self-attention is computed as:
- Q = X W Q Q = XW_Q Q = X W Q , with W Q ∈ R D × D q W_Q \in \mathbb{R}^{D \times D_q} W Q ∈ R D × D q
- K = X W K K = XW_K K = X W K , with W K ∈ R D × D k W_K \in \mathbb{R}^{D \times D_k} W K ∈ R D × D k
- V = X W V V = XW_V V = X W V , with W V ∈ R D × D v W_V \in \mathbb{R}^{D \times D_v} W V ∈ R D × D v
- Causal mask M M M to prevent future token access
The final output is:
Attention ( X ; Q , K , V ) = softmax ( Q K ⊤ ⋅ M d k ) V \text{Attention}(X; Q, K, V) = \text{softmax}\left( \frac{QK^\top \cdot M}{\sqrt{d_k}} \right)V Attention ( X ; Q , K , V ) = softmax ( d k Q K ⊤ ⋅ M ) V
Here’s a minimal PyTorch equivalent using a causal mask:
import torch.nn.functional as F
import math
d_k = K.shape[-1]
attention_scores = (Q @ K.T) / math.sqrt(d_k)
# Lower triangular mask to prevent future token access
causal_mask = torch.tril(torch.ones(input_seq_length, input_seq_length))
masked_scores = attention_scores.masked_fill(causal_mask == 0, float('-inf'))
attention_weights = F.softmax(masked_scores, dim=-1)
output = attention_weights @ VWhere Redundancy Creeps In
In autoregressive generation, the model generates one token at a time. With each step, it recomputes Q Q Q , K K K , and V V V for the entire sequence , even though the earlier tokens haven’t changed.
new_token_emb = torch.randn(1, dim_model)
extended_input = torch.cat([input_ids_emb, new_token_emb], dim=0)
Q_ext = extended_input @ W_q
K_ext = extended_input @ W_k
V_ext = extended_input @ W_v
# (output_ext would be computed using Q_ext, K_ext, V_ext + masking)To confirm the redundancy:
torch.testing.assert_close(K, K_ext[:input_seq_length]) # test pass
torch.testing.assert_close(V, V_ext[:input_seq_length]) # test passThese checks show that for all but the newest token, K K K and V V V are identical to previously computed values.
Original (5×5): Extended (6×6):
■ ■ ■ ■ ■ ■ ■ ■ ■ ■ □
■ ■ ■ ■ ■ ■ ■ ■ ■ ■ □
■ ■ ■ ■ ■ → ■ ■ ■ ■ ■ □
■ ■ ■ ■ ■ ■ ■ ■ ■ ■ □
■ ■ ■ ■ ■ ■ ■ ■ ■ ■ □
□ □ □ □ □ □- ■ = Already computed and reused
- □ = Recomputed unnecessarily
Most of the attention computation is repeated needlessly. This gets more expensive as sequences grow.
How KV Caching Fixes It
To eliminate this inefficiency, we use KV Caching :
- After processing the initial prompt, we cache the computed keys ( K K K ) and values ( V V V ) for each layer.
- During generation, we only compute K K K and V V V for the new token , and append them to the cache.
- We compute Q Q Q for the current token and use it with the cached K K K and V V V to get the output.
This changes generation from full-sequence re-computation to a lightweight, incremental update.
✅ In practice, this cache is a per-layer dictionary with keys "key" and "value", each of shape ( batch_size , num_heads , seq_len_cached , head_dim ).
This is the foundation of how modern LLMs can generate long outputs efficiently.
KV Caching in nanoVLM: From Theory to Practice
Now that we understand the theory behind KV Caching, let’s see how it’s implemented in practice inside our nanoVLM repository. This is an ideal testbed, as it's a super concise and self-contained codebase.
KV caching is enabled across three key components in our model:
- The Attention block that uses and updates the KV cache
- The Language model that tracks cache per layer
- The Generation loop that separates prefill (the initial pass with the input prompt) and sequential decode phases
1. Updating KV Cache in the Attention Block
In the LanguageModelGroupedAttention class, we modify the forward function to accept and update a cache of keys and values ( block_kv_cache ).
Previously, the model recomputed K K K and V V V at every generation step. Now we only compute K new K_{\text{new}} K new , V new V_{\text{new}} V new for the current token, and append them to the cached values.
def forward(self, x, cos, sin, attention_mask=None, block_kv_cache=None):
is_prefill = block_kv_cache is None
B, T_curr, C = x.size()
# Project inputs to Q, K, V
q_curr, k_curr, v_curr = project_current_tokens(x)
q, k_rotated = apply_rotary_pos_embd(q_curr, k_curr, cos, sin)
if not is_prefill and block_kv_cache['key'] is not None:
# Append new keys and values to the cache
k = torch.cat([block_kv_cache['key'], k_rotated], dim=2)
v = torch.cat([block_kv_cache['value'], v_curr], dim=2)
else:
# First pass (prefill) — no cache
k, v = k_rotated, v_curr
block_kv_cache = {'key': k, 'value': v}
return attention_output, block_kv_cache2. Tracking Cache Across Layers
In the LanguageModel class, we introduce layer-wise cache tracking . The start_pos argument helps the model compute correct rotary positional encodings for newly generated tokens.
def forward(self, x, kv_cache=None, start_pos=0):
T_curr = x.size(1)
position_ids = torch.arange(start_pos, start_pos + T_curr, device=x.device)
cos, sin = self.rotary_embd(position_ids)
for i, block in enumerate(self.blocks):
# Pass per-layer KV cache
x, kv_cache[i] = block(x, cos, sin, attention_mask, kv_cache[i])
return x, kv_cache- kv_cache : A list of dictionaries, one per transformer layer, holding previous keys and values.
- start_pos : Ensures that rotary embeddings are aligned with current generation index.
3. Prefill vs Decode in the Generation Loop
The biggest architectural change is in the generate() method of the VisionLanguageModel .
We split generation into two stages :
- PREFILL PHASE: Encode the full prompt and build the initial cache.
- DECODE PHASE: Generate tokens one at a time using cached keys/values.
PREFILL PHASE (cache construction)
[Prompt: "What is"] → [Transformer] → [Cache: K, V for all layers]
DECODE PHASE (token-by-token)
[Token: "the"] → [Q("the") + cached K/V] → [next token: "?"] → ...Here’s the corresponding code:
# PREFILL: Process the input prompt, fill the cache
prompt_output, kv_cache_list = self.forward(
inputs,
kv_cache=None,
start_pos=0
)
# DECODE: Generate one token at a time using cached K/V
for i in range(max_new_tokens):
next_token = sample_from(prompt_output)
decode_output, kv_cache_list = self.forward(
next_token,
kv_cache=kv_cache_list,
start_pos=current_position # updated with each step
)
prompt_output = decode_outputBy separating these phases, we avoid redundant computation and dramatically speed up inference, especially for long prompts.
Summary of Changes
Summary: Why KV Caching Matters
KV caching eliminates unnecessary computation during autoregressive generation, enabling faster and more efficient inference, especially in long sequences and real-time applications. This is a trade-off between speed and memory, and its drawbacks can be more complex code and restricting fancier inference schemes, like beam-search, etc. KV caching is a popular method for speeding up LLM inference, making it possible to run them on consumer hardware, and now you know how it works too!
More Articles from our Blog
Training and Finetuning Multimodal Embedding & Reranker Models with Sentence Transformers
Multimodal Embedding & Reranker Models with Sentence Transformers
Community

Thanks for this great article! I'm learning a lot from the nanoVLM project. I'm not an expert in gen ai but I noticed the attention calculation example seems to be missing the scaling √(d_k). Is this intentional for simplification?
d_k = K.shape[-1]
attention_scores = (Q @ K.T) / math.sqrt(d_k)From my understanding this scaling prevents the dot product growing too large and control the softmax region
- 1 reply
This is such a good catch!
Would you like to raise a PR to the blog post with the changes to the code?
Here is the source for the blog post: https://github.com/huggingface/blog/blob/main/kv-cache.md

Nice read, I found the prefill and decode explanation very intuitive. Good job 👏

made this visual representation of what happens inside the attention mechanism when using kv caching. thought i'd share it with the community 🤗
- 1 reply
VERY COOL! Thanks for sharing.
Hi Team, kv_cache only for text? Is it doing for images in this Articles.
- 1 reply
caching results can be used for diffusion applications as well, although not similar to KV caching since kv caching is optimized for next token prediction while in diffusion the full sequence already exists. the short answer to your question is yes kv caching is only for next token prediction but there are other caching techniques out there for other tasks try checking what PrunaAI has been doing to optimize diffusion models, here's a link to one of their previous presentations : LINKEDIN_POST

· Sign up or log in to comment
- +107