
Ulysses Sequence Parallelism: Training with Million-Token Contexts
- +21


Training large language models on long sequences has become essential for building capable AI systems. As models are increasingly used for tasks like document analysis, code understanding, complex reasoning, and RAG workloads, the need to process sequences of hundreds of thousands—or even millions—of tokens has grown dramatically. To put this in perspective, an average book is roughly 250k tokens, so training on multi-document contexts or book-length inputs requires handling sequences well beyond what fits on a single GPU. However, training with such long contexts presents significant memory challenges: the attention computation scales quadratically with sequence length, quickly exceeding GPU memory for contexts beyond tens of thousands of tokens.
Ulysses Sequence Parallelism (part of the Arctic Long Sequence Training (ALST) protocol from Snowflake AI Research) provides an elegant solution by distributing the attention computation across multiple GPUs through attention head parallelism. In this post, we'll explore how Ulysses works and how it's been integrated across the Hugging Face ecosystem—from Accelerate to the Transformers Trainer and TRL's SFTTrainer.
Contents
- The Challenge of Long Sequence Training
- How Ulysses Works
- Integration with Accelerate
- Integration with Transformers Trainer
- Integration with TRL's SFTTrainer
- Comparing Ulysses and Ring Attention
- Best Practices
- Benchmarks
- Resources
The Challenge of Long Sequence Training
The attention mechanism in transformers scales quadratically with sequence length. For a sequence of length n n n , standard attention requires O ( n 2 ) O(n^2) O ( n 2 ) FLOPs and O ( n 2 ) O(n^2) O ( n 2 ) memory to compute and store the attention score matrix. Optimized implementations like FlashAttention reduce the memory to O ( n ) O(n) O ( n ) by tiling the computation and never materializing the full attention matrix—but the O ( n 2 ) O(n^2) O ( n 2 ) compute remains. For very long sequences (32k+ tokens), even with FlashAttention, training still pushes the limits of single-GPU memory.
Consider these scenarios where long-context training is essential:
- Document understanding : Processing entire books, legal documents, or research papers
- Code analysis : Understanding large codebases with multiple interconnected files
- Reasoning tasks : Models that "think" step-by-step may generate thousands of tokens during inference
- Retrieval-augmented generation : Incorporating many retrieved passages into the context
Traditional data parallelism doesn't help here—each GPU still needs to process the full sequence inside the attention block. We need a way to split the sequence itself across multiple devices.
How Ulysses Works
Ulysses Sequence Parallelism (SP), introduced in the DeepSpeed Ulysses paper , takes a clever approach: in addition to splitting on the sequence dimension, it also partitions the attention heads across GPUs.
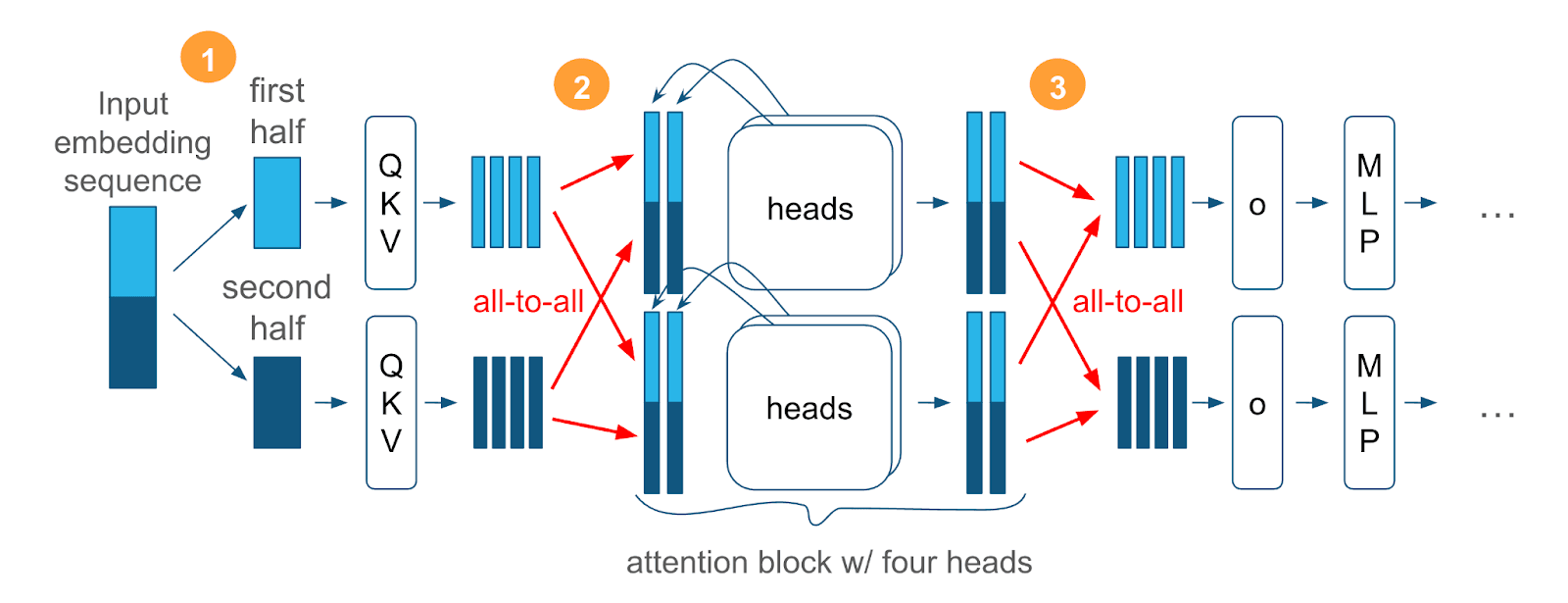
Here's how it works:
- Sequence Sharding : The input sequence is split along the sequence dimension across P P P GPUs. Each GPU i i i holds tokens [ i ⋅ n / P , ( i + 1 ) ⋅ n / P ) [i \cdot n/P, (i+1) \cdot n/P) [ i ⋅ n / P , ( i + 1 ) ⋅ n / P ) .
- QKV Projection : Each GPU computes the query, key, and value projections for its local sequence chunk.
- All-to-All Communication : An all-to-all collective operation redistributes the data so that each GPU holds all sequence positions after the projections, but only for a subset of attention heads.
- Local Attention : Each GPU computes attention for its assigned heads using standard attention mechanisms (FlashAttention or SDPA).
- All-to-All Communication : Another all-to-all operation reverses the redistribution, returning to sequence-sharded format.
- Output Projection : Each GPU computes the output projection for its local sequence chunk.
The key insight is that attention heads are independent—each head can be computed separately. By trading sequence locality for head locality, Ulysses enables efficient parallelization with relatively low communication overhead.
Communication Complexity
Ulysses requires two all-to-all operations per attention layer, with total communication volume of O ( n ⋅ d / P ) O(n \cdot d / P) O ( n ⋅ d / P ) per GPU, where:
- n n n is the sequence length
- d d d is the hidden dimension
- P P P is the parallelism degree
Ring Attention communicates O ( n ⋅ d ) O(n \cdot d) O ( n ⋅ d ) per GPU — a factor of P P P more — via P − 1 P-1 P − 1 sequential point-to-point transfers around the ring. Ulysses also benefits from lower latency because all-to-all can exploit full bisectional bandwidth in a single collective step, whereas Ring Attention serializes over P − 1 P-1 P − 1 hops.
Integration with Accelerate
Accelerate provides the foundation for Ulysses sequence parallelism through its ParallelismConfig class and DeepSpeed integration.
Configuration
from accelerate import Accelerator
from accelerate.utils import ParallelismConfig, DeepSpeedSequenceParallelConfig
parallelism_config = ParallelismConfig(
sp_backend="deepspeed",
sp_size=4, # Split across 4 GPUs
dp_shard_size=1, # Must satisfy: dp_replicate × dp_shard × sp_size = num_processes
sp_handler=DeepSpeedSequenceParallelConfig(
sp_seq_length=None, # None for variable-length sequences
sp_seq_length_is_variable=True,
sp_attn_implementation="flash_attention_2", # or "sdpa"
),
)
accelerator = Accelerator(parallelism_config=parallelism_config)Key Parameters
Using the Accelerator
When you call accelerator.prepare() , Ulysses is automatically set up:
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3.1-8B")
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-5)
# This registers the model with Ulysses and wraps the dataloader
model, optimizer, dataloader = accelerator.prepare(model, optimizer, dataloader)The prepare() call:
- Registers the model with DeepSpeed's UlyssesSPAttentionHF
- Wraps the dataloader with UlyssesSPDataLoaderAdapter to handle sequence sharding
- Automatically injects shift_labels for correct loss computation
Loss Aggregation
With Ulysses, each GPU computes loss on different parts of the sequence. The losses must be aggregated properly, weighted by the number of valid tokens per rank. If you're using the Transformers Trainer or TRL's SFTTrainer , this is handled automatically—the code below is only needed when writing a custom Accelerate training loop:
sp_size = parallelism_config.sp_size
if sp_size > 1:
from deepspeed.utils import groups
sp_group = groups._get_sequence_parallel_group()
# Gather losses and token counts from all SP ranks
losses_per_rank = torch.distributed.nn.functional.all_gather(loss, group=sp_group)
good_tokens = (batch["shift_labels"] != -100).view(-1).sum()
good_tokens_per_rank = torch.distributed.nn.functional.all_gather(good_tokens, group=sp_group)
# Weighted aggregation
total_loss = sum(
losses_per_rank[i] * good_tokens_per_rank[i]
for i in range(sp_size)
if good_tokens_per_rank[i] > 0
)
loss = total_loss / max(sum(good_tokens_per_rank), 1)
accelerator.backward(loss)The weighted loss aggregation ensures correct gradients when tokens are unevenly distributed across ranks (e.g., when some ranks contain only padding or masked out prompt tokens).
Both Ulysses and Ring Attention use position_ids instead of attention_mask for causal masking during training. A 4D attention mask at these sequence lengths would be just as prohibitive as the attention scores themselves—at 128k tokens, that's another ~1TB tensor. Position IDs achieve the same causal behavior with O ( n ) O(n) O ( n ) memory instead of O ( n 2 ) O(n^2) O ( n 2 ) . During evaluation/inference, DeepSpeed's SP attention layer can bypass the SP operations entirely (via disable_in_eval ) and fall back to the model's default attention implementation.
Integration with Transformers Trainer
The Transformers Trainer provides seamless Ulysses integration through TrainingArguments.parallelism_config . It handles all the SP-specific details automatically—dataloader wrapping, sequence sharding, and loss aggregation—so you don't need to write any of the custom loss code shown above.
Configuration
Just pass the same parallelism_config from above into TrainingArguments :
from transformers import TrainingArguments
training_args = TrainingArguments(
parallelism_config=parallelism_config, # same ParallelismConfig as above
per_device_train_batch_size=1,
)What the Trainer Handles Automatically
- Dataloader Wrapping : After model preparation, the Trainer wraps the dataloader with UlyssesSPDataLoaderAdapter
- Loss Computation : The compute_loss method detects SP mode and routes to specialized _deepspeed_sp_compute_loss which handles: Gathering losses across SP ranks
- Computing valid token counts per rank
- Weighted loss aggregation
Batch Size Calculation : The effective data parallel world size accounts for SP:
dp_world_size = world_size // sp_sizeDataloader Length Adjustment : Training step calculations are adjusted for SP's effect on iteration count
Launch Command
Use an accelerate config file or command-line arguments:
accelerate launch \
--config_file deepspeed_ulysses.yaml \
train.py \
--per_device_train_batch_size 1Integration with TRL SFTTrainer
TRL's SFTTrainer builds on the Transformers Trainer and adds specific optimizations for supervised fine-tuning with long sequences.
Configuration
from trl import SFTConfig, SFTTrainer
from accelerate.utils import ParallelismConfig, DeepSpeedSequenceParallelConfig
parallelism_config = ParallelismConfig(
sp_backend="deepspeed",
sp_size=2,
dp_shard_size=2, # 2D parallelism: SP × DP = 4 GPUs
sp_handler=DeepSpeedSequenceParallelConfig(
sp_seq_length_is_variable=True,
sp_attn_implementation="flash_attention_2",
),
)
training_args = SFTConfig(
...,
parallelism_config=parallelism_config,
max_length=32768,
pad_to_multiple_of=2, # Must equal sp_size
per_device_train_batch_size=1,
)
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=dataset,
)
trainer.train()Key SFTConfig Parameters for Ulysses
Accelerate Config File
Create alst_ulysses_4gpu.yaml :
compute_environment: LOCAL_MACHINE
distributed_type: DEEPSPEED
mixed_precision: bf16
num_processes: 4
deepspeed_config:
zero_stage: 3
seq_parallel_communication_data_type: bf16
parallelism_config:
parallelism_config_sp_size: 2
parallelism_config_sp_backend: deepspeed
parallelism_config_dp_shard_size: 2
parallelism_config_sp_seq_length_is_variable: true
parallelism_config_sp_attn_implementation: flash_attention_2Complete Training Command
accelerate launch --config_file alst_ulysses_4gpu.yaml \
trl/scripts/sft.py \
--model_name_or_path meta-llama/Llama-3.1-8B \
--dataset_name trl-lib/Capybara \
--max_length 32768 \
--packing \
--pad_to_multiple_of 2 \
--per_device_train_batch_size 1Shift Labels Handling
The SFTTrainer automatically handles pre-shifted labels when Ulysses is enabled:
# When using SP, labels are pre-shifted by the dataloader adapter
# The trainer detects this and uses shift_labels directly
labels = inputs["labels"] if "shift_labels" not in inputs else None
# Loss computation uses the pre-shifted labels
if "shift_labels" in inputs:
shift_logits = outputs.logits.contiguous()
shift_labels = inputs["shift_labels"]
else:
shift_logits = outputs.logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()Comparing Ulysses and Ring Attention
Both Ulysses and Ring Attention enable long-context training, but they have different characteristics:
When to Choose Ulysses vs Ring Attention
Since switching between the two only requires changing the accelerate config, we recommend trying both and comparing performance and memory usage on your specific setup. The main constraint is that Ulysses requires num_heads >= sp_size , while Ring Attention has no such limitation.
Best Practices
1. Sequence Length Divisibility
Always ensure your sequence length is divisible by sp_size :
training_args = SFTConfig(
pad_to_multiple_of=4, # For sp_size=4
max_length=32768, # Must be divisible by 4
)2. Use Flash Attention
Flash Attention 2 provides cleaner output and better performance than SDPA:
parallelism_config = ParallelismConfig(
sp_handler=DeepSpeedSequenceParallelConfig(
sp_attn_implementation="flash_attention_2",
),
)Use Flash Attention 3 for Hopper and look out for Flash Attention 4 release for Blackwell (FA2 on Blackwell is quite slow).
3. Combine with DeepSpeed ZeRO
For very large models, combine Ulysses with ZeRO Stage 3:
deepspeed_config:
zero_stage: 3
offload_optimizer:
device: cpuIf the model is huge, you can offload the params as well by adding to the above:
offload_param:
device: cpu5. Use memory fragmentation-friendly PyTorch allocator
This environment variable will allow for a longer sequence length:
export PYTORCH_ALLOC_CONF=expandable_segments:True6. 2D Parallelism Configuration
Balance SP and DP for your GPU count:
Remember: dp_replicate_size × dp_shard_size × sp_size = num_processes
7. Liger-Kernel
If your desired model architecture is supported by Liger-Kernel , it is fully compatible with Ulysses SP and can be enabled with a single flag:
training_args = SFTConfig(
use_liger_kernel=True,
)The main memory saving comes from FusedLinearCrossEntropy which avoids materializing the full logits tensor during loss calculation. The savings grow with longer sequences where the logits tensor is larger.
Additionally, you can enable TiledMLP to further extend sequence length — like FusedLinearCrossEntropy , it saves working memory by tiling large matrix operations.
8. Token Distribution Across Ranks
You don't need to worry about manually balancing tokens across SP ranks—the loss aggregation code handles uneven distributions gracefully (including ranks with zero valid tokens). With random batching over a reasonably sized dataset, the distribution evens out statistically over training.
Benchmarks
To quantify the benefits of Ulysses SP, we trained Qwen3-4B on the Gutenberg English streaming dataset using TRL's SFTTrainer. All experiments ran on H100 80GB GPUs with DeepSpeed ZeRO-3, CPU optimizer offloading, gradient checkpointing, and flash-attn2 as the attention backend.
Setup
The benchmark runs in the table above use the same global batch size (8 micro-batches), cosine learning-rate schedule, and seed, so those benchmark loss curves are directly comparable.
Loss Curve Matching Diagnostics (4 GPU)
To verify SP-vs-DP loss equivalence, we ran controlled 4-GPU A/B experiments with identical seed, model, optimizer, learning-rate schedule, and data order.
Methodology for Fair DP vs SP Comparison
Compared setups:
- DP=4, SP=1, GAS=1 (baseline)
- DP=1, SP=4, GAS=4 (Ulysses SP)
For fair comparison, GAS must scale with SP :
- Ulysses SP splits the sequence across SP ranks, so each SP rank sees roughly 1/SP of the sequence tokens per micro-step.
- If GAS is unchanged, each optimizer step in SP aggregates fewer total tokens than the DP baseline.
- Setting GAS=SP keeps effective tokens per optimizer step matched: DP tokens/step: dp_world_size * micro_batch * seq_len * GAS = 4 * B * L * 1
- SP tokens/step: dp_world_size * micro_batch * (L/SP) * GAS * SP_ranks = 1 * B * (L/4) * 4 * 4 = 4 * B * L
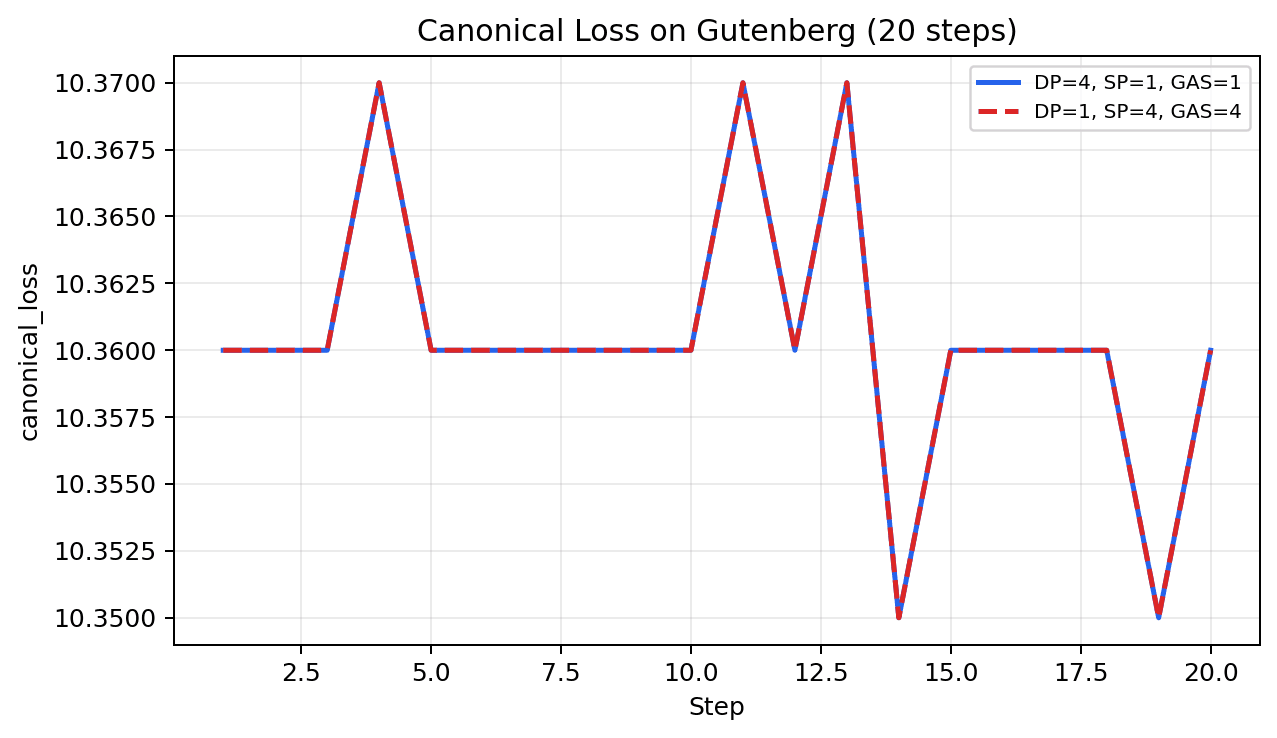
Measured over 20 steps on 4 GPUs in controlled equivalence harnesses:
Takeaway: under matched token budget, SP and non-SP match on canonical token-normalized loss. The remaining difference is in trainer-reported logging ( loss ), not in the underlying cross-entropy objective.
Memory Reduction
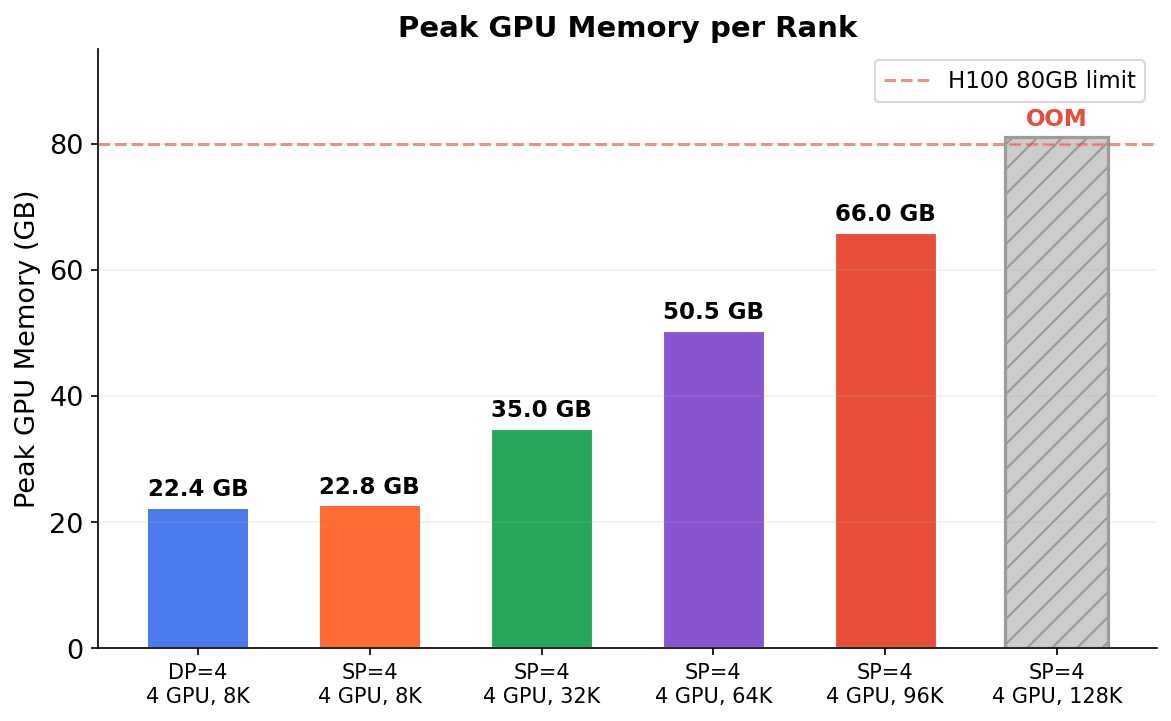
At 8K tokens, DP=4 and SP=4 use nearly the same memory per GPU (~22 GB with ZeRO-3). The advantage of SP is that it enables scaling to much longer sequences: at 96K tokens (12x longer), peak memory is 66 GB — still within the H100's 80 GB capacity. At 128K, the model OOMs, establishing the practical limit for this configuration. DP=4 without SP cannot scale beyond 8K for this model.
Throughput
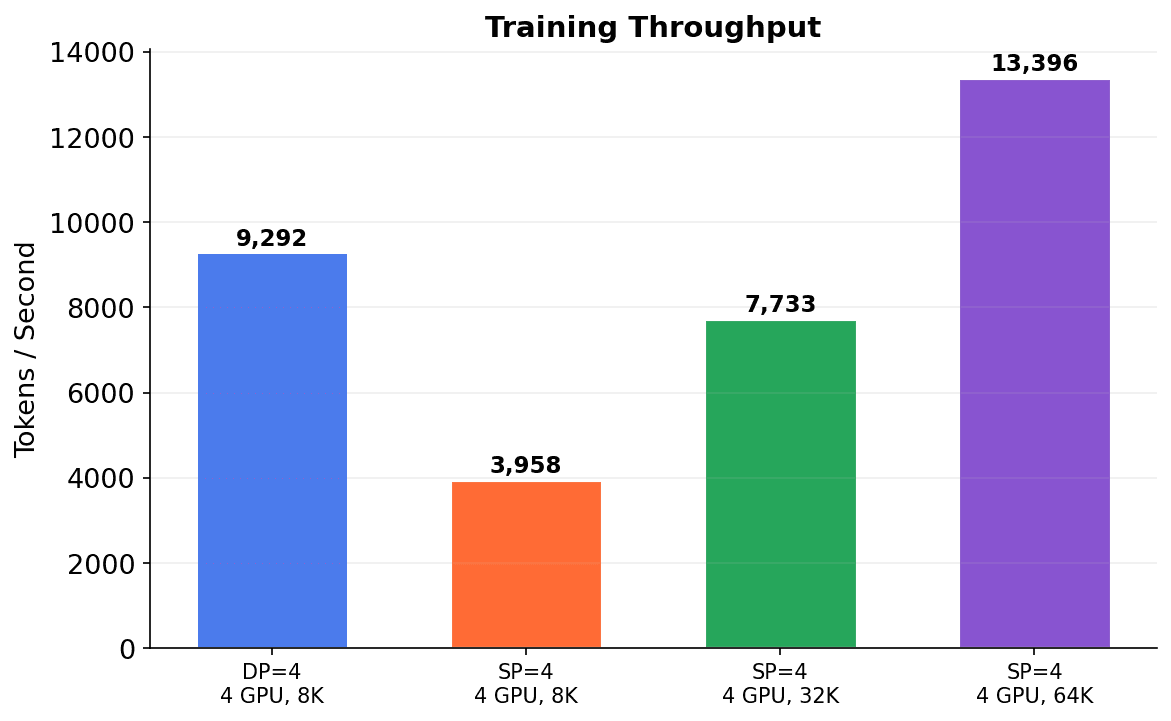
At the same sequence length (8K), SP=4 has comparable throughput to the single-GPU baseline — the all-to-all communication overhead is minimal on NVLink-connected GPUs. The real benefit comes from longer sequences: as sequence length grows, the quadratic attention computation dominates over communication and other overheads, making each training step increasingly compute-efficient. Each step also processes proportionally more tokens, so throughput scales with sequence length. At 64K, SP=4 processes 13,396 tokens/second — 3.7x the baseline.
These results use only 4 GPUs with SP=4. With 8 GPUs (SP=8), you can push to even longer sequences — up to 256K+ tokens — or use 2D parallelism (SP=4, DP=2) to combine long-context training with data-parallel throughput.
Requirements
- HF Accelerate: deepspeed>=0.18.1 accelerate>=1.12
- HF Trainer: deepspeed>=0.18.1 accelerate>=1.12 transformers>=5.0
- HF TRL: deepspeed>=0.18.1 accelerate>=1.12 transformers>=5.0 trl>=0.18.0
Use flash_attention_2 for Ampere GPUs, or flash_attention_3 for Hopper GPUs. Wait for flash_attention_4 on Blackwell 🕰.
Resources
Documentation
- Accelerate: Context Parallelism Guide
- TRL: Distributing Training
- DeepSpeed Sequence Parallelism
Examples
- Accelerate ALST Example
- TRL Accelerate Configs
Papers
- Arctic Long Sequence Training: Scalable And Efficient Training For Multi-Million Token Sequences
- DeepSpeed Ulysses: System Optimizations for Enabling Training of Extreme Long Sequence Transformer Models
Related Blog Posts
- Accelerate ND-Parallel: A Guide to Efficient Multi-GPU Training
- Understanding Ulysses and Ring Attention
- Enabling Long-Context Training with Sequence Parallelism in Axolotl
Models mentioned in this article 1
Datasets mentioned in this article 1
Papers mentioned in this article 3
More Articles from our Blog
Tricks from OpenAI gpt-oss YOU 🫵 can use with transformers
- +3
Accelerate ND-Parallel: A guide to Efficient Multi-GPU Training
- +1
Community
· Sign up or log in to comment
- +15