
SmolVLM2: Bringing Video Understanding to Every Device
- +331








TL;DR: SmolVLM can now watch 📺 with even better visual understanding
SmolVLM2 represents a fundamental shift in how we think about video understanding - moving from massive models that require substantial computing resources to efficient models that can run anywhere. Our goal is simple: make video understanding accessible across all devices and use cases, from phones to servers.
We are releasing models in three sizes (2.2B, 500M and 256M), MLX ready (Python and Swift APIs) from day zero. We've made all models and demos available in this collection .
Want to try SmolVLM2 right away? Check out our interactive chat interface where you can test visual and video understanding capabilities of SmolVLM2 2.2B through a simple, intuitive interface.
Table of Contents
- SmolVLM2: Bringing Video Understanding to Every Device TL;DR: SmolVLM can now watch 📺 with even better visual understanding
- Table of Contents
- Technical Details SmolVLM2 2.2B: Our New Star Player for Vision and Video
- Going Even Smaller: Meet the 500M and 256M Video Models
- Suite of SmolVLM2 Demo applications iPhone Video Understanding
- VLC media player integration
- Video Highlight Generator
- Transformers Video Inference
- Multiple Image Inference
- Swift MLX
Technical Details
We are introducing three new models with 256M, 500M and 2.2B parameters. The 2.2B model is the go-to choice for vision and video tasks, while the 500M and 256M models represent the smallest video language models ever released .
While they're small in size, they outperform any existing models per memory consumption. Looking at Video-MME (the go-to scientific benchmark in video), SmolVLM2 joins frontier model families on the 2B range and we lead the pack in the even smaller space.
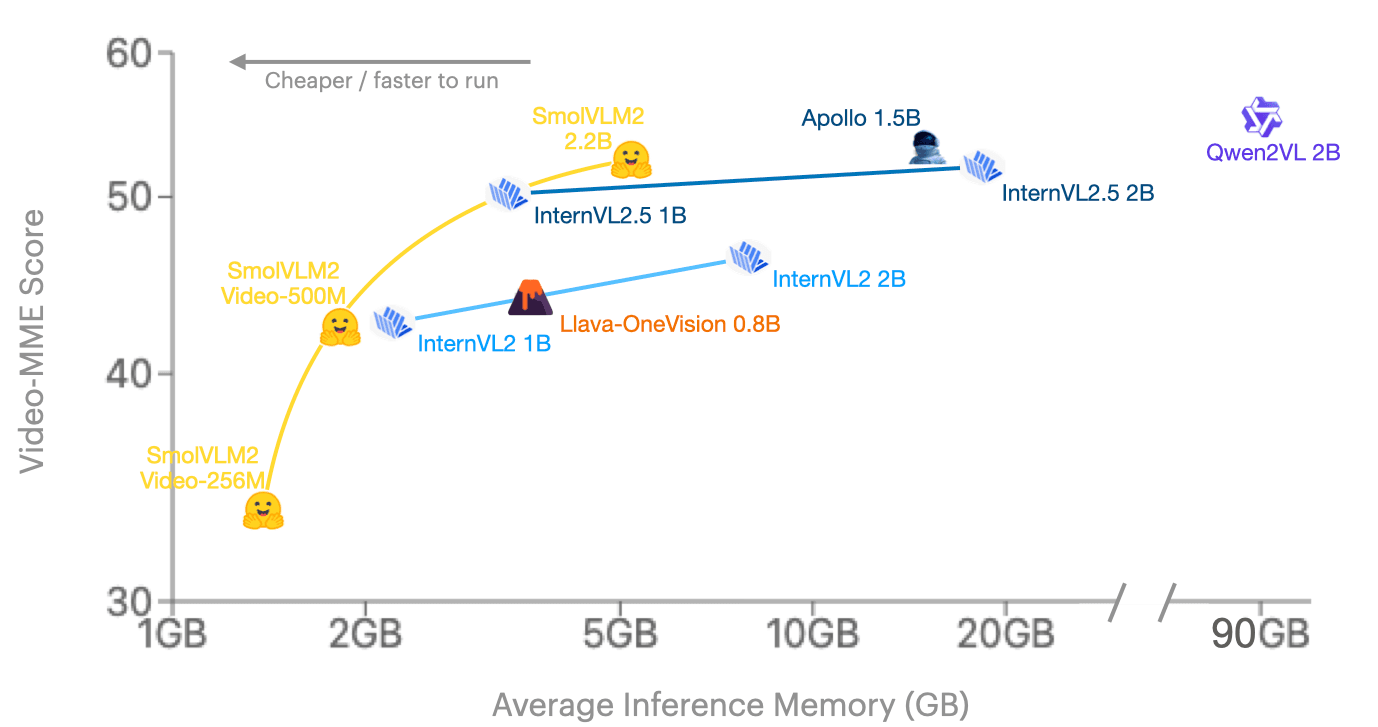
Video-MME stands out as a comprehensive benchmark due to its extensive coverage across diverse video types, varying durations (11 seconds to 1 hour), multiple data modalities (including subtitles and audio), and high-quality expert annotations spanning 900 videos totaling 254 hours. Learn more here .
SmolVLM2 2.2B: Our New Star Player for Vision and Video
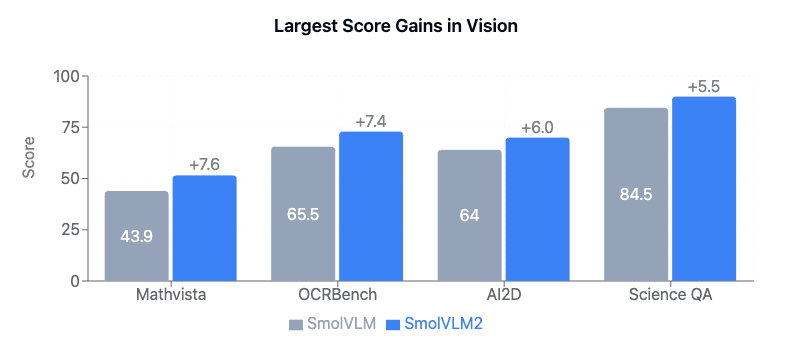
Compared with the previous SmolVLM family, our new 2.2B model got better at solving math problems with images, reading text in photos, understanding complex diagrams, and tackling scientific visual questions. This shows in the model performance across different benchmarks:
When it comes to video tasks, 2.2B is a good bang for the buck. Across the various scientific benchmarks we evaluated it on, we want to highlight its performance on Video-MME where it outperforms all existing 2B models.
We were able to achieve a good balance on video/image performance thanks to the data mixture learnings published in Apollo: An Exploration of Video Understanding in Large Multimodal Models
It’s so memory efficient, that you can run it even in a free Google Colab.
# Install transformers from `main` or from this stable branch:
!pip install git+https://github.com/huggingface/transformers@v4.49.0-SmolVLM-2
from transformers import AutoProcessor, AutoModelForImageTextToText
import torch
model_path = "HuggingFaceTB/SmolVLM2-2.2B-Instruct"
processor = AutoProcessor.from_pretrained(model_path)
model = AutoModelForImageTextToText.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
_attn_implementation="flash_attention_2"
).to("cuda")
messages = [
{
"role": "user",
"content": [
{"type": "video", "path": "path_to_video.mp4"},
{"type": "text", "text": "Describe this video in detail"}
]
},
]
inputs = processor.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
).to(model.device, dtype=torch.bfloat16)
generated_ids = model.generate(**inputs, do_sample=False, max_new_tokens=64)
generated_texts = processor.batch_decode(
generated_ids,
skip_special_tokens=True,
)
print(generated_texts[0])Going Even Smaller: Meet the 500M and 256M Video Models
Nobody dared to release such small video models until today.
Our new SmolVLM2-500M-Video-Instruct model has video capabilities very close to SmolVLM 2.2B, but at a fraction of the size: we're getting the same video understanding capabilities with less than a quarter of the parameters 🤯.
And then there's our little experiment, the SmolVLM2-256M-Video-Instruct. Think of it as our "what if" project - what if we could push the boundaries of small models even further? Taking inspiration from what IBM achieved with our base SmolVLM-256M-Instruct a few weeks ago, we wanted to see how far we could go with video understanding. While it's more of an experimental release, we're hoping it'll inspire some creative applications and specialized fine-tuning projects.
Suite of SmolVLM2 Demo applications
To demonstrate our vision in small video models, we've built three practical applications that showcase the versatility of these models.
iPhone Video Understanding
VLC media player integration
Video Highlight Generator
Using SmolVLM2 with Transformers and MLX
We make SmolVLM2 available to use with transformers and MLX from day zero. In this section, you can find different inference alternatives and tutorials for video and multiple images.
Transformers
The easiest way to run inference with the SmolVLM2 models is through the conversational API – applying the chat template takes care of preparing all inputs automatically.
You can load the model as follows.
# Install transformers from `main` or from this stable branch:
!pip install git+https://github.com/huggingface/transformers@v4.49.0-SmolVLM-2
from transformers import AutoProcessor, AutoModelForImageTextToText
import torch
processor = AutoProcessor.from_pretrained(model_path)
model = AutoModelForImageTextToText.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
_attn_implementation="flash_attention_2"
).to("cuda")Video Inference
You can pass videos through a chat template by passing in {"type": "video", "path": {video_path} . See below for a complete example.
messages = [
{
"role": "user",
"content": [
{"type": "video", "path": "path_to_video.mp4"},
{"type": "text", "text": "Describe this video in detail"}
]
},
]
inputs = processor.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
).to(model.device, dtype=torch.bfloat16)
generated_ids = model.generate(**inputs, do_sample=False, max_new_tokens=64)
generated_texts = processor.batch_decode(
generated_ids,
skip_special_tokens=True,
)
print(generated_texts[0])Multiple Image Inference
In addition to video, SmolVLM2 supports multi-image conversations. You can use the same API through the chat template, providing each image using a filesystem path, an URL, or a PIL.Image object:
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "What are the differences between these two images?"},
{"type": "image", "url": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg"},
{"type": "image", "url": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/0052a70beed5bf71b92610a43a52df6d286cd5f3/diffusers/rabbit.jpg"},
]
},
]
inputs = processor.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
).to(model.device, dtype=torch.bfloat16)
generated_ids = model.generate(**inputs, do_sample=False, max_new_tokens=64)
generated_texts = processor.batch_decode(
generated_ids,
skip_special_tokens=True,
)
print(generated_texts[0])Inference with MLX
To run SmolVLM2 with MLX on Apple Silicon devices using Python, you can use the excellent mlx-vlm library . First, you need to install mlx-vlm from this branch using the following command:
pip install git+https://github.com/pcuenca/mlx-vlm.git@smolvlmThen you can run inference on a single image using the following one-liner, which uses the unquantized 500M version of SmolVLM2 :
python -m mlx_vlm.generate \
--model mlx-community/SmolVLM2-500M-Video-Instruct-mlx \
--image https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg \
--prompt "Can you describe this image?"We also created a simple script for video understanding. You can use it as follows:
python -m mlx_vlm.smolvlm_video_generate \
--model mlx-community/SmolVLM2-500M-Video-Instruct-mlx \
--system "Focus only on describing the key dramatic action or notable event occurring in this video segment. Skip general context or scene-setting details unless they are crucial to understanding the main action." \
--prompt "What is happening in this video?" \
--video /Users/pedro/Downloads/IMG_2855.mov \
--prompt "Can you describe this image?"Note that the system prompt is important to bend the model to the desired behaviour. You can use it to, for example, describe all scenes and transitions, or to provide a one-sentence summary of what's going on.
Swift MLX
The Swift language is also supported through the mlx-swift-examples repo , which is what we used to build our iPhone app.
Until our in-progress PR is finalized and merged, you have to compile the project from this fork , and then you can use the llm-tool CLI on your Mac as follows.
For image inference:
./mlx-run --debug llm-tool \
--model mlx-community/SmolVLM2-500M-Video-Instruct-mlx \
--prompt "Can you describe this image?" \
--image https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg \
--temperature 0.7 --top-p 0.9 --max-tokens 100Video analysis is also supported, as well as providing a system prompt. We found system prompts to be particularly helpful for video understanding, to drive the model to the desired level of detail we are interested in. This is a video inference example:
./mlx-run --debug llm-tool \
--model mlx-community/SmolVLM2-500M-Video-Instruct-mlx \
--system "Focus only on describing the key dramatic action or notable event occurring in this video segment. Skip general context or scene-setting details unless they are crucial to understanding the main action." \
--prompt "What is happening in this video?" \
--video /Users/pedro/Downloads/IMG_2855.mov \
--temperature 0.7 --top-p 0.9 --max-tokens 100If you integrate SmolVLM2 in your apps using MLX and Swift, we'd love to know about it! Please, feel free to drop us a note in the comments section below!
Fine-tuning SmolVLM2
You can fine-tune SmolVLM2 on videos using transformers 🤗 We have fine-tuned the 500M variant in Colab on video-caption pairs in VideoFeedback dataset for demonstration purposes. Since the 500M variant is small, it's better to apply full fine-tuning instead of QLoRA or LoRA, meanwhile you can try to apply QLoRA on cB variant. You can find the fine-tuning notebook here .
Citation information
You can cite us in the following way:
@article{marafioti2025smolvlm,
title={SmolVLM: Redefining small and efficient multimodal models},
author={Andrés Marafioti and Orr Zohar and Miquel Farré and Merve Noyan and Elie Bakouch and Pedro Cuenca and Cyril Zakka and Loubna Ben Allal and Anton Lozhkov and Nouamane Tazi and Vaibhav Srivastav and Joshua Lochner and Hugo Larcher and Mathieu Morlon and Lewis Tunstall and Leandro von Werra and Thomas Wolf},
journal={arXiv preprint arXiv:2504.05299},
year={2025}
}Read More
We would like to thank Raushan Turganbay, Arthur Zucker and Pablo Montalvo Leroux for their contribution of the model to transformers.
We are looking forward to seeing all the things you'll build with SmolVLM2! If you'd like to learn more about the SmolVLM family of models, feel free to read the following:
SmolVLM2 - Collection with Models and Demos
Models mentioned in this article 2
Datasets mentioned in this article 1
Collections mentioned in this article 1
More Articles from our Blog
SmolVLM - small yet mighty Vision Language Model
- +1
Llama can now see and run on your device - welcome Llama 3.2
- +3
Community

📻 🎙️ Hey, I generated an AI podcast about this blog post, check it out!
This podcast is generated via ngxson/kokoro-podcast-generator , using DeepSeek-R1 and Kokoro-TTS .
when run this script: python -m mlx_vlm.generate --model mlx-community/SmolVLM2-500M-Video-Instruct-mlx --image https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg --prompt "Can you describe this image?"
====================================== test errror: Files: [' https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg']
Prompt: <|im_start|>User: Can you describe this image? Assistant: Traceback (most recent call last): File "", line 198, in _run_module_as_main File "", line 88, in _run_code File "/opt/homebrew/Caskroom/miniconda/base/envs/playwright/lib/python3.12/site-packages/mlx_vlm/generate.py", line 156, in main() File "/opt/homebrew/Caskroom/miniconda/base/envs/playwright/lib/python3.12/site-packages/mlx_vlm/generate.py", line 141, in main output = generate( ^^^^^^^^^ File "/opt/homebrew/Caskroom/miniconda/base/envs/playwright/lib/python3.12/site-packages/mlx_vlm/utils.py", line 1115, in generate for response in stream_generate(model, processor, prompt, image, **kwargs): ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/opt/homebrew/Caskroom/miniconda/base/envs/playwright/lib/python3.12/site-packages/mlx_vlm/utils.py", line 1016, in stream_generate inputs = prepare_inputs( ^^^^^^^^^^^^^^^ File "/opt/homebrew/Caskroom/miniconda/base/envs/playwright/lib/python3.12/site-packages/mlx_vlm/utils.py", line 806, in prepare_inputs processor.tokenizer.pad_token = processor.tokenizer.eos_token ^^^^^^^^^^^^^^^^^^^ File "/opt/homebrew/Caskroom/miniconda/base/envs/playwright/lib/python3.12/site-packages/transformers/tokenization_utils_base.py", line 1108, in getattr raise AttributeError(f"{self. class . name } has no attribute {key}") AttributeError: GPT2TokenizerFast has no attribute tokenizer. Did you mean: '_tokenizer'?
Hi @ leexiaobo2006 ! You need to install transformers from main , or from this stable branch:
pip install git+https://github.com/huggingface/transformers@v4.49.0-SmolVLM-2https://koshurai.medium.com/a-comprehensive-tutorial-on-using-smolvlm2-for-image-and-video-analysis-faa10e0710a6
here is a tutorial on how to use SMOLVLM2 on colab for free using T4 GPU Free Tier
- 3 replies
Nice! Would you like to publish the same content as a community article , to maximize visibility?
where to find th code of app demo @ pcuenq
- 1 reply
- Code: https://github.com/huggingface/huggingsnap
- App Store link: https://apps.apple.com/us/app/huggingsnap/id6742157364
Nice work!
Do you know where is the code repo for Video Highlight Generator? Thanks! @ pcuenq
- 2 replies
Hi! You can find it here: https://huggingface.co/spaces/HuggingFaceTB/SmolVLM2 Then press three dots -> Clone repository
i have seen vlms which are great but they do inference via frame by frame which can lead to false alarms
can this model understand the video(take chunks of frame and uderstand the nature of video ) ?
Hi - what is the longest duration of video this can handle ?
Could someone share how video processing in this model is handled?
Hi, can I ask if SmolVLM2 supports semantic segmentation ?
@ dangmanhtruong1995 hello, unfortunately no. I think all vision LMs that support segmentation support instance segmentation, you can then aggregate masks together to come up with semantic ones. PaliGemma2 does it, maybe SAM3 (it takes in short prompts like "red car" and not "red car on the left")

SmolVLM2 feels like a genuinely practical step forward, especially in a world where not everyone has access to high-end hardware but still wants meaningful video insights... the idea of shifting from heavy, resource-hungry systems to something lightweight and widely usable just makes sense, and it opens the door for more everyday applications.... from mobile users to small developers. . .. without needing complex setups, which is why I find this approach both timely and necessary, even without needing to point to any specific source URL to see its value clearly.
I understand but some confussion there anyone help me?
· Sign up or log in to comment
- +325