Nemotron-Personas-Japan: ソブリン AI のための合成データセット
- +3






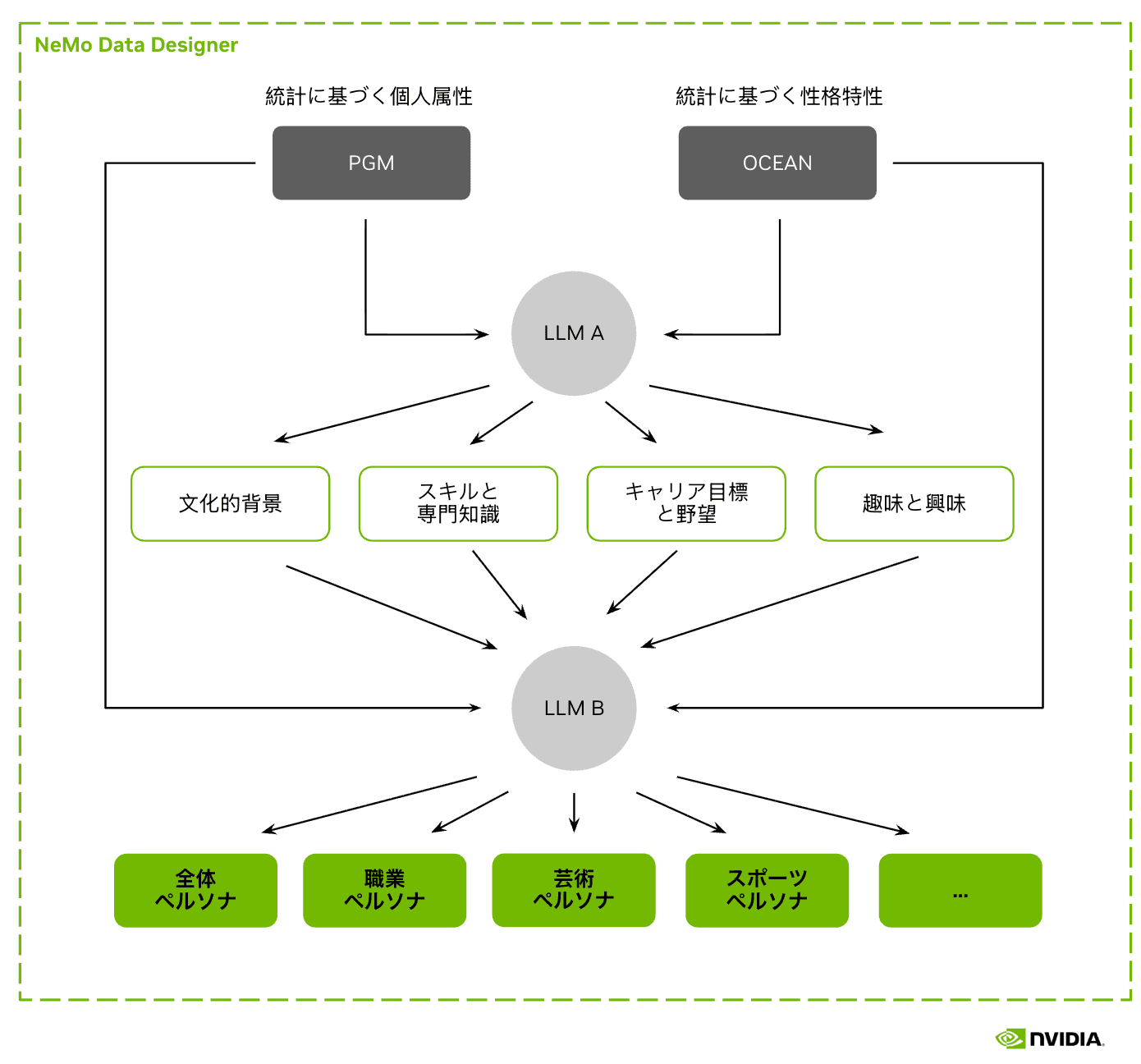
実世界分布に基づいた日本人ペルソナのための複合AIアプローチ
日本の AI の未来に向けたオープンデータ
高品質で多様なトレーニングデータなしに、日本文化を真に理解するAIを構築することはこれまでほぼ不可能でした。これを変えるため、NVIDIAは、日本の人口統計、地理的分布、文化的特性に沿ったペルソナを含む初の オープン合成データセット 、 Nemotron-Personas-Japan を公開しました。 CC BY 4.0 ライセンスのもと提供される本データセットは、機微な個人データに依存することなく日本社会を反映した AI システム構築のための、 プライバシー保護と規制対応を両立した基盤 を提供します。
NVIDIA のエンタープライズ向け合成データ生成システム、 NeMo Data Designer を用いて作成されたNemotron-Personas-Japan は、すでに広く利用されている US Personas データセット の成功を機に日本版として開発されました。本リリースは、各国・地域における ソブリン AI 開発 を支援する合成ペルソナデータセットとデータ構築方法のグローバルコレクションの第一弾です。
本データセットは、 Nemotron モデル をはじめとするオープンソースの 大規模言語モデル(LLM) とシームレスに連携するよう設計されており、企業向けチャットボットから各種ドメインの AI エージェントに至るまで、 日本語 AI アプリケーション向けのファインチューンを容易に 行えるようになっています。
データセットの内容
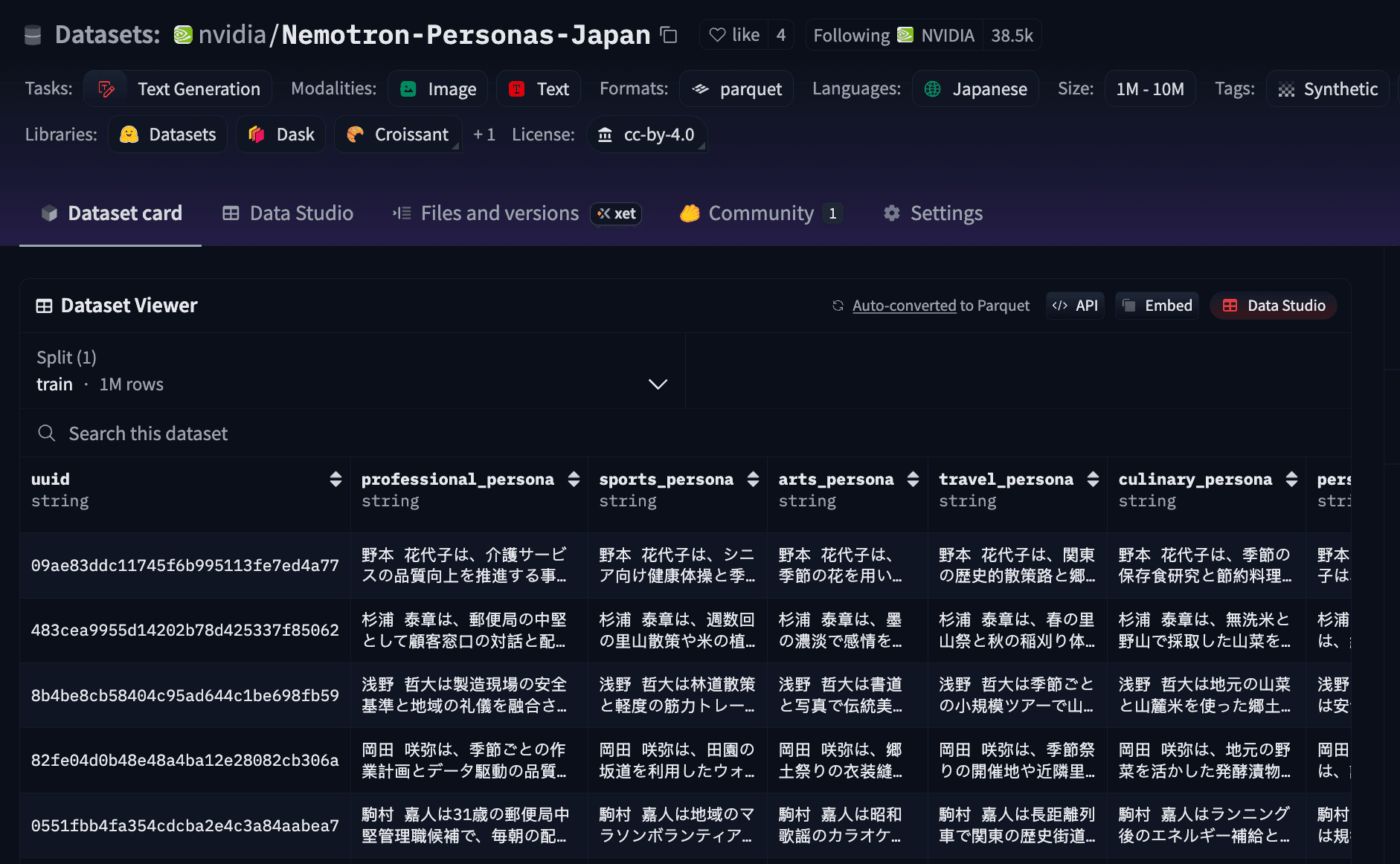
- 合計 600万件(各レコードにつき6ペルソナ、100万レコード) の自然な日本語で記述されたペルソナ
- 1レコードあたり22項目 :6つのペルソナ関連項目と、公式の人口統計・労働統計に基づいた16のコンテキスト項目
- 総トークン数約14億: そのうち約8億5000万がペルソナ関連トークン
- 約95万件 の固有の名前:合成データ生成で前例のない多様性
- 日本の労働力を反映した 1500 以上 の職種カテゴリー
- 人口・地域・性格特性軸を 網羅的にカバー
- 多様なペルソナタイプ :職業、スポーツ、芸術、旅行、料理
- 自然言語によるペルソナ属性: 文化的背景、スキルと専門性、キャリア目標・志向、趣味や関心
- CC BY 4.0 ライセンスに基づき 、商用・非商用を問わず利用可能
Nemotron-Personas-Japanの構築方法
データ生成パイプライン
NVIDIAの合成データ生成用マイクロサービスである NeMo Data Designer を用いて構築されています。この複合AIシステムは、複雑な Jinja テンプレート、Pydantic による検証、構造化出力、自動リトライ、および複数の生成バックエンドのサポートを可能にします。これらは、このような大規模な合成データセットの生成に必要なツール群です。さらに、以下のモデルも活用しています。
- 統計に基づいた生成を実現するための 確率的グラフィカル モデル(Apache-2.0)
- 日本語文章生成のための GPT-OSS-120B(Apache-2.0)
日本の文化的背景の反映
Nemotron-Personas-Japan は、日本の公的な人口統計および労働統計に整合するよう設計されると同時に、AI トレーニングにおいて重要な以下の点を考慮して生成されました:
- 教育 :国の統計で学位レベルが一括分類されている場合、モデルが異なる教育経路を反映できるよう、より細かい区分を導入しました。
- 職業 :トレーニングに使用する職業の幅を広げるため、追加カテゴリー(事業主や専門職種など)を組み込みました。
- ライフステージ :統計上ではあまり表に出ない学生、退職者、失業状態といったシナリオをモデル化し、より現実的なペルソナを表現できるようにしました。
- 文化的特性 :日本の社会的・文化的特徴を組み込み、AI システムが地域固有の規範をより適切に反映できるようにしました。
- デジタル デバイド :年齢層ごとのデジタルリテラシーの差を考慮し、日本における実際のテクノロジー利用状況を反映しました。
プライバシーを保護した設計
このデータセットには、個人を特定できる情報(PII)は一切含まれていません。年齢、名前、職業などは公的な統計データの分布に基づいていますが、存命・故人問わず、実在の人物と結びつくことはありません。全てのペルソナは完全に人工的に生成されているため、実際の文化的パターンを保ちながらも、個人のプライバシーを損なうことなくトレーニングに利用できます。
想定するユーザ
Nemotron-Personas-Japanは、日本のソブリン AI システムを開発する日本のモデル開発者向けに設計されています。現在、LLM開発者が使用する訓練データのほとんどは英語であり、日本やインドなど各地域の開発者は、母国語で高品質なデータを入手するのに苦労しています。
本データセットを含め、NVIDIA の Nemotron-Personas の一連の取り組みは、こうした課題を直接解決するものです。地域固有のニュアンスを捉えつつ、開発者が地域固有の言語で多様かつ複雑なデータを生成できるようサポートします。データセットは国勢調査データ、日本人の命名規則、文化的特徴など地域のコンテキストに基づき、すべて母語で生成しています。
そのため、日本で自分たちのモデルの採用を拡大し、日本の文化的コンテキストを理解したい すべての AI モデルの開発者の方々のお役に立てれば幸いです。
実用的な AI アプリケーションへの利用
本データセットに含まれる合成ペルソナを以下のようなことに活用できます:
- マルチターンの会話合成 :ペルソナを「シード」として活用し、人間らしい対話データセットを作成
- ドメイン固有の AI アシスタントの開発 :文化的配慮が可能な AI アシスタントを構築するためのデータセットを作成
- バイアステストと公平性 :モデルや AI エージェントシステムが、地方と都市、異なる年齢層、あるいは多様な教育水準などにわたってどのように機能するかを評価し、日本社会のあらゆる層に対して公平に働くAIを実現
合成ペルソナデータの重要性
AI 開発には、実世界の人々を反映した多様で高品質な訓練データへのアクセスが長らく課題でした。企業向け AI の開発はプライベートデータが主流となっており、研究者、スタートアップ、そして特に利用可能なデータが少ない地域のAI開発者にとって障壁となっていました。
- データの多様性 :日本の全人口層を反映することで、偏った学習や モデル崩壊 を防ぎます。
- 文化的信頼性 :欧米中心のデータセットへの依存を減らし、 ソブリンAIシステム の開発を支援します。
- プライバシーとコンプライアンス :日本の 個人情報保護法(PIPA) の要件および将来の AI ガバナンスを満たします。
Nemotron-Personas-Japan を CC BY 4.0 のもとで公開することで、企業レベルの高品質な合成データへのアクセスを可能とし、従来のコスト、プライバシーの懸念、地理的な制約といった障壁なしに、文化的背景を正確に反映した AI システムを誰でも構築できるようになりました。
今すぐ使ってください
以下のコマンドで本データセットをダウンロードできます。 日本文化と言語を真に理解する AI の開発にお役立てください。
from datasets import load_dataset
ds = load_dataset("nvidia/Nemotron-Personas-Japan")本番用アプリケーション構築のための活用例:
- ペルソナを会話生成のシードとして活用する
- 文化的背景を反映したデータでモデルをファインチューニングする
- 日本の人口構成全体を反映する、パーソナライズされたエンジンを構築する
- 日本のコンテキストを備えたドメイン特化型 AI エージェントを開発する
日本でソブリン AI を開発するモデル開発者から、より広範な地域での利用を目指すグローバルな開発者まで、 Nemotron-Personas-Japan データセットは、アプリケーションに必要な本格的かつプライバシーに配慮した基盤を提供します。
Datasets mentioned in this article 1
More from this author
Introducing NVIDIA Nemotron 3 Nano Omni: Long-Context Multimodal Intelligence for Documents, Audio and Video Agents
Adaptive Ultrasound Imaging with Physics-Informed NV-Raw2Insights-US AI
Community
· Sign up or log in to comment