
Introducing RTEB: A New Standard for Retrieval Evaluation
- +137







TL;DR – We’re excited to introduce the beta version of the Retrieval Embedding Benchmark (RTEB) , a new benchmark designed to reliably evaluate the retrieval accuracy of embedding models for real-world applications. Existing benchmarks struggle to measure true generalization, while RTEB addresses this with a hybrid strategy of open and private datasets. Its goal is simple: to create a fair, transparent, and application-focused standard for measuring how models perform on data they haven’t seen before.
The performance of many AI applications, from RAG and agents to recommendation systems, is fundamentally limited by the quality of search and retrieval. As such, accurately measuring the retrieval quality of embedding models is a common pain point for developers. How do you really know how well a model will perform in the wild?
This is where things get tricky. The current standard for evaluation often relies on a model's "zero-shot" performance on public benchmarks. However, this is, at best, an approximation of a model's true generalization capabilities. When models are repeatedly evaluated against the same public datasets, a gap emerges between their reported scores and their actual performance on new, unseen data.
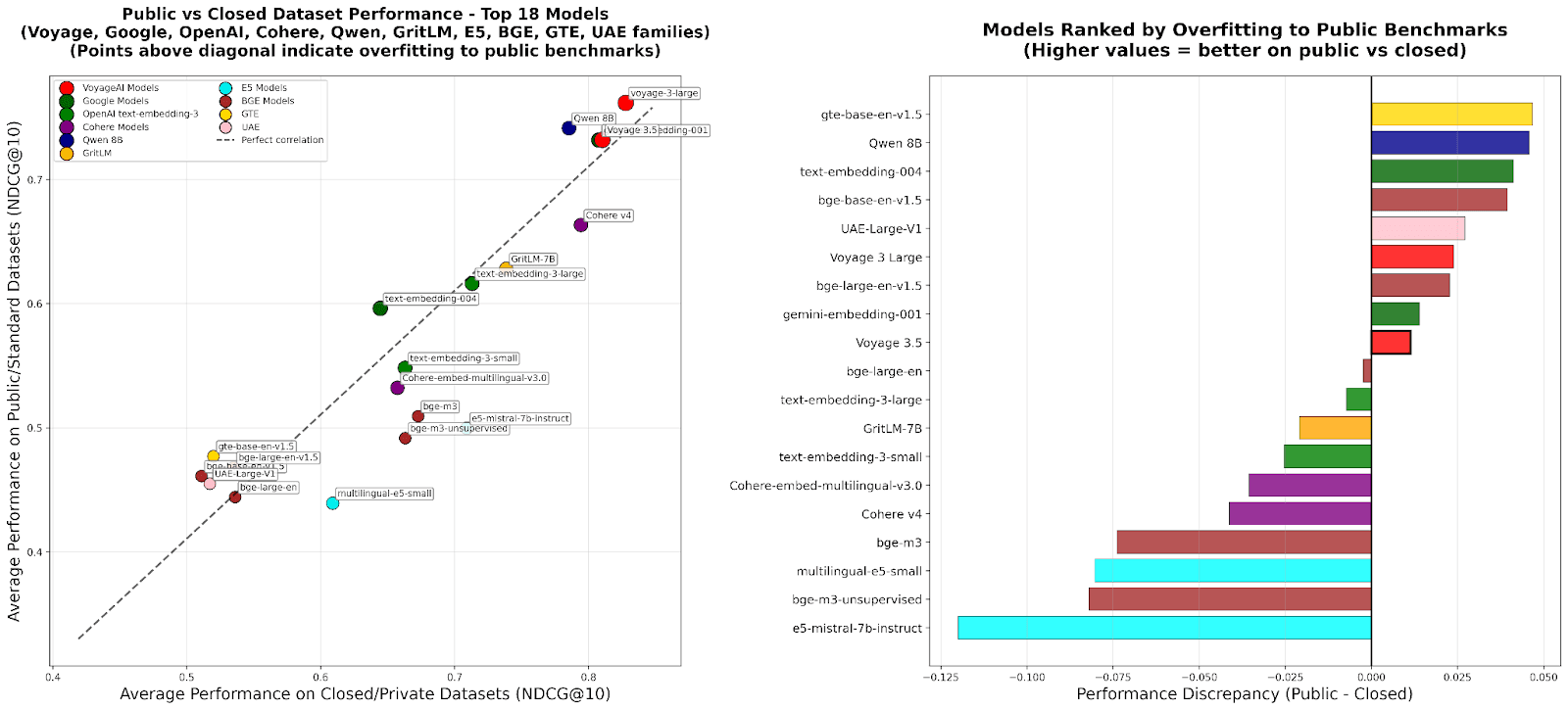
To address these challenges, we developed RTEB, a benchmark built to provide a reliable standard for evaluating retrieval models.
Why Existing Benchmarks Fall Short
While the underlying evaluation methodology and metrics (such as NDCG@10) are well-known and robust, the integrity of existing benchmarks is often set back by the following issues:
The Generalization Gap . The current benchmark ecosystem inadvertently encourages "teaching to the test." When training data sources overlap with evaluation datasets, a model's score can become inflated, undermining a benchmark's integrity. This practice, whether intentional or not, is evident in the training datasets of several models. This creates a feedback loop where models are rewarded for memorizing test data rather than developing robust, generalizable capabilities.
Because of the above, models with a lower zero-shot score [1] may perform very well on the benchmark, without generalizing to new problems. For this reason, models with slightly lower benchmark performance and a higher zero-shot score are often recommended instead.
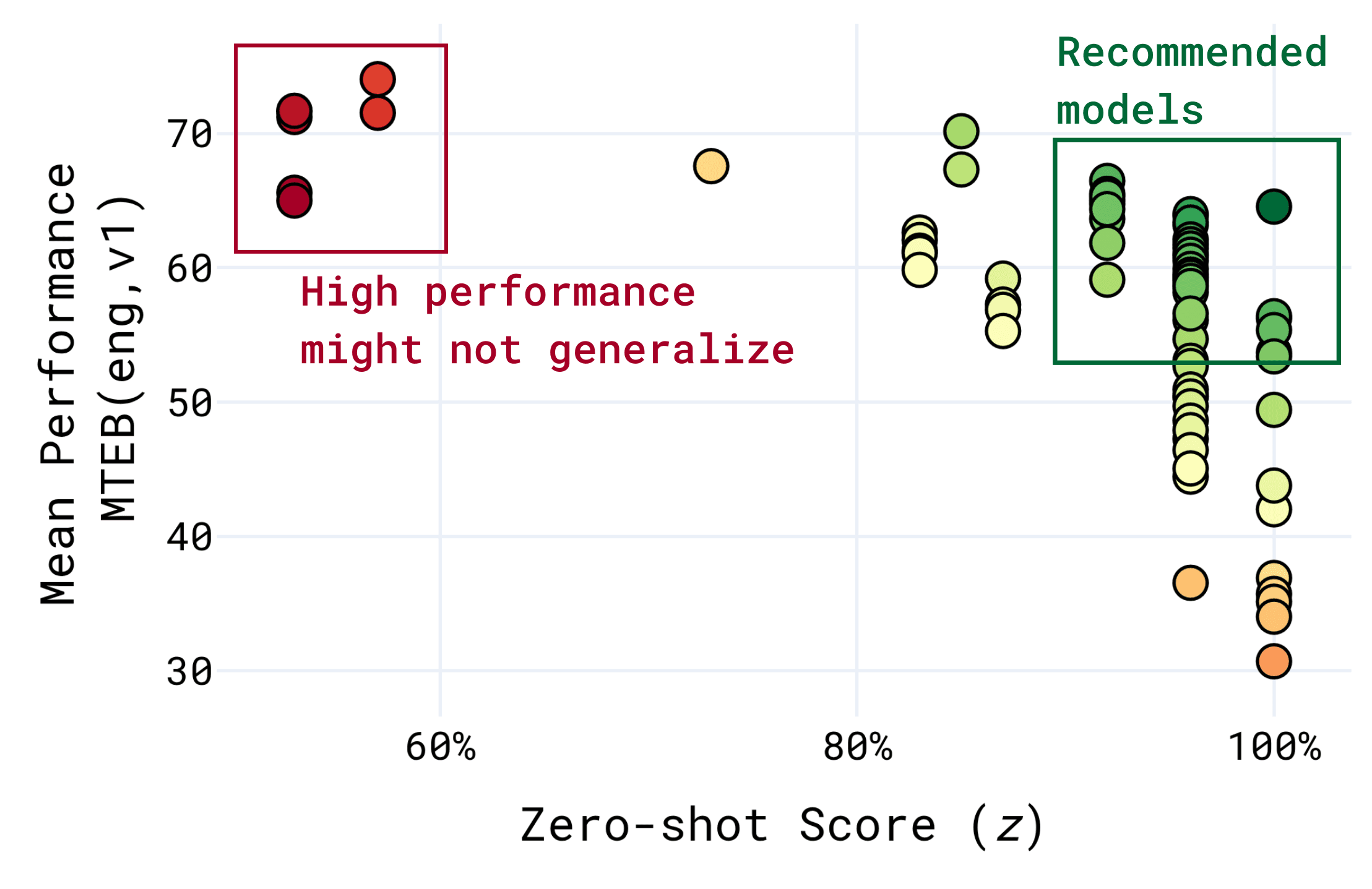
Misalignment with Today’s AI Applications . Many benchmarks are poorly aligned with the enterprise use cases that developers are building today. They often rely on academic datasets or on retrieval tasks derived from QA datasets, which, while useful in their own right, were not designed to evaluate retrieval and can fail to capture the distributional biases and complexities encountered in real-world retrieval scenarios. Benchmarks which do not possess these issues are often too narrow, focusing on a single domain like code retrieval, making them unsuitable for evaluating general-purpose models.
Introducing RTEB
Today, we’re excited to introduce the Retrieval Embedding Benchmark (RTEB) . Its goal is to create a new, reliable, high-quality benchmark that measures the true retrieval accuracy of embedding models.
A Hybrid Strategy for True Generalization
To combat benchmark overfitting, RTEB implements a hybrid strategy using both open and private datasets:
- Open Datasets: The corpus, queries, and relevance labels are fully public. This ensures transparency and allows any user to reproduce the results.
- Private Datasets: These datasets are kept private, and evaluation is handled by the MTEB maintainers to ensure impartiality. This setup provides a clear, unbiased measure of a model’s ability to generalize to unseen data. For transparency, we provide descriptive statistics, a dataset description, and sample (query, document, relevance) triplets for each private dataset.
This hybrid approach encourages the development of models with broad, robust generalization. A model with a significant performance drop between the open and the private datasets would suggest overfitting, providing a clear signal to the community. This is already apparent with some models, which show a notable drop in performance on RTEB's private datasets.
Built for Real-World Domains
RTEB is designed with a particular emphasis on enterprise use cases. Instead of a complex hierarchy, it uses simple groups for clarity. A single dataset can belong to multiple groups (e.g., a German law dataset exists in both the "law" and "German" groups).
- Multilingual in Nature: The benchmark datasets cover 20 languages, from common ones like English or Japanese to rarer languages such as Bengali or Finnish.
- Domain-Specific Focus: The benchmark includes datasets from critical enterprise domains like law, healthcare, code, and finance.
- Efficient Dataset Sizes: Datasets are large enough to be meaningful (at least 1k documents and 50 queries) without being so large that they make evaluation time-consuming and expensive.
- Retrieval-First Metric: The default leaderboard metric is NDCG@10 , a gold-standard measure for the quality of ranked search results.
A complete list of the datasets can be found below. We plan to continually update both the open as well as closed portion with different categories of datasets and actively encourage participation from the community; please open an issue on the MTEB repository on GitHub if you would like to suggest other datasets.
Open
Closed
Launching RTEB: A Community Effort
RTEB is launching today in beta. We believe building a robust benchmark is a community effort, and we plan to evolve RTEB based on feedback from developers and researchers alike. We encourage you to share your thoughts, suggest new datasets, find issues in existing datasets and help us build a more reliable standard for everyone. Please feel free to join the discussion or open an issue in the MTEB repository on Github .
Limitations and Future Work
To highlight areas for improvement we want to be transparent about RTEB's current limitations and our plans for the future.
- Benchmark Scope: RTEB is focused on realistic, retrieval-first use cases. Highly challenging synthetic datasets are not a current goal but could be added in the future.
- Modality: The benchmark currently evaluates text-only retrieval. We plan to incorporate text-image and other multimodal retrieval tasks in future releases.
- Language Coverage: We are actively working to expand our language coverage, particularly for major languages like Chinese and Arabic, as well as more low-resource languages. If you know of high-quality datasets that fits these criteria please let us know.
- Repurposing of QA dataset : About 50% of the current retrieval datasets are repurposed from QA datasets, which might lead to issues such as a strong lexical overlap between the question and the context, favoring models that rely on keyword matching over true semantic understanding.
- Private datasets: To test for generalization, we utilize private datasets that are only accessible to MTEB maintainers. To maintain fairness, all maintainers commit to not publishing models trained on these datasets and only testing on these private datasets through public channels, ensuring no company or individual receives unfair advantages.
Our goal is for RTEB to become a community-trusted standard for retrieval evaluation.
The RTEB leaderboard is available today on Hugging Face as a part of the new Retrieval section on the MTEB leaderboard. We invite you to check it out, evaluate your models, and join us in building a better, more reliable benchmark for the entire AI community.
[1] Zero-shot score is the proportion of the evaluation set which the model provider have explicitly stated to have trained on. This typically only includes the training split.
Datasets mentioned in this article 9
Papers mentioned in this article 1
More Articles from our Blog
Introducing HELMET: Holistically Evaluating Long-context Language Models
- +3
Letting Large Models Debate: The First Multilingual LLM Debate Competition
- +8
Community

Observed a fun fact: English-only models tend to get worse performance on closed datasets, while multilingual models are better at closed dataset.
Is it because the baseline, MTEB, is a benchmark merely in English, and RTEB is multilingual? It's natural that multilingual model get better performance on multilingual benchmark instead of English.
RTEB is by default multilingual, however it has an English subset (currently denoted as RTEB(eng, beta) or RTEB English on the leaderboard selection menu)
There is also an argument that multilingual models are more robust to phenomena such as code-switching and foreign terms.

Hi!
Are you planning on releasing an academic paper on RTEB?
· Sign up or log in to comment
- +131