
Finetuning olmOCR to be a faithful OCR-Engine
- +13


Recently, the Allen Institute for Artificial Intelligence introduced olmOCR , a model that has demonstrated impressive results in converting PDFs into clean, linearized plain text while preserving structured content. However, olmOCR's primary use case is to provide more training data for Large Language Models and therefore ignores extraneous information like headers and footers in documents. While this is beneficial for generating training data, it is insufficient for real business applications where crucial information often resides in the header and footer part of the text (think of invoices, for example). This article describes how we fine-tuned the original olmOCR-7B-0225-preview to be a faithful OCR engine, enabling it to support a broader range of applications.

In this example, crucial information in the header and footer marked as red, is ignored by olmOCR.
Problem of pipeline-based OCR-Engines
Optical Character Recognition has broad applications in various business use cases. For a long time, the predominant paradigm for AI-based OCR engines have been pipeline-based systems. These are comprised of multiple machine-learning components, e.g., section segmentation, table parsing, character recognition, etc., chained together. However, one fundamental flaw of this approach is that the extracted results mostly do not flatten the context in a way that adheres to logical reading order, also known as linearization. This is particularly challenging for layout-rich documents with floating elements like multi-column documents with floating diagrams, headers, footers, etc. With the recent advent of Vision Language Models, a lot of effort has been put into leveraging them as alternative OCR systems to tackle this problem.
Starting Point: olmOCR-7B-0225-preview
During our testing of the olmOCR model published on Hugging Face for business applications like invoice parsing, we observed a consistent omission of important information in the headers and footers. This was expected, as the dataset used to train olmOCR, olmOCR-mix-0225, intentionally excludes extraneous information in these areas to maintain a natural reading flow, as such information cannot be meaningfully predicted in the context of next-token prediction for training.
To address this limitation and enable comprehensive information extraction, we utilized Qwen2.5-VL-72B-Instruct to generate a dataset of 8,000 documents that captures all relevant information, as one would expect from a reliable OCR engine. We based our training setup on the open-sourced olmOCR training pipeline, utilizing 4 gradient accumulation steps on an 8xH100 Nvidia node, for a total of 2.5 epochs. The default hyperparameters worked quite well for us, eliminating the need for resource-intensive hyperparameter search. The experiment tracking with MlLflow showed the following results:
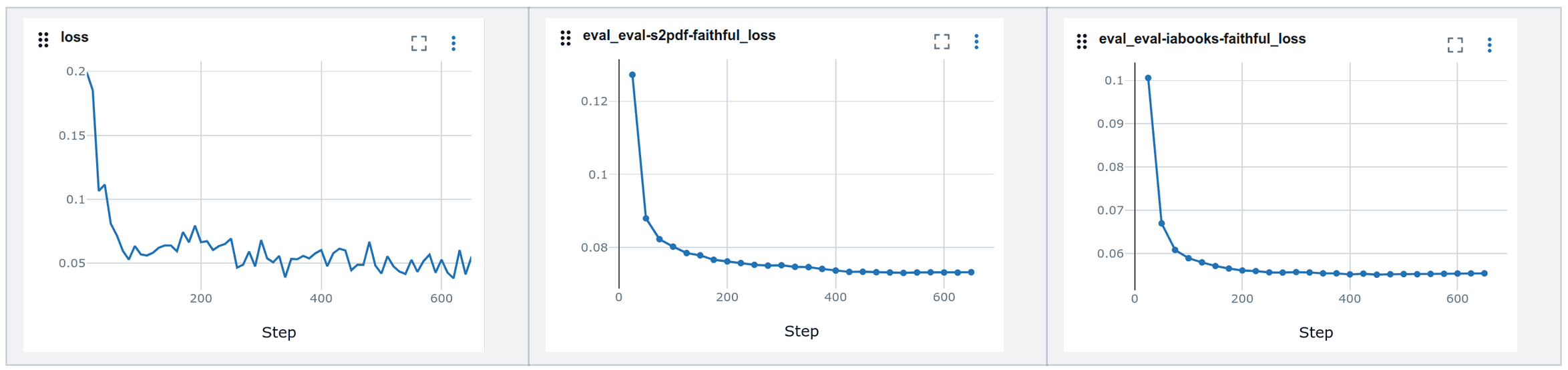
For evaluation, we utilized a customized version of the olmOCR-mix-0225 eval-datasets, which include header and footer information, also acquired with Qwen2.5-VL-72B-Instruct.
Once the training was done, it was time to put our model to the test.
Comparison between original and fine-tuned olmOCR
We did a qualitative assessment of documents where crucial information was missing after parsing its content. Our inference setup is identical to the one by olmOCR, utilizing the special prompting strategy called document anchoring that preserves any born-digital content from each page. This technique extracts the raw tex blocks and position information to prompt VLMs alongside the rasterized image.
We provide several examples of the original response and the response of the fine-tuned model below. We marked crucial missing information in red.

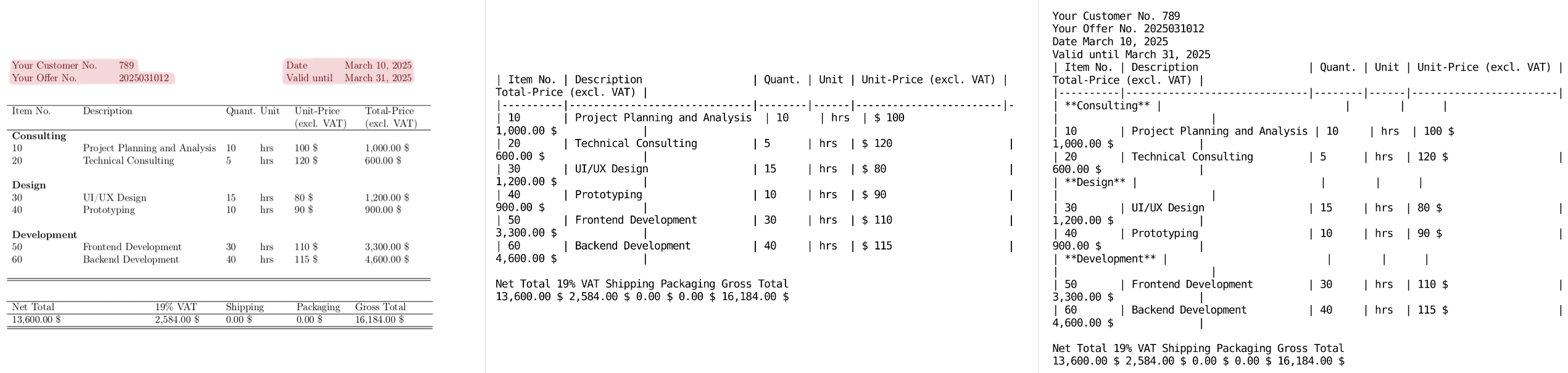


Overall, we are happy with the results, as now all information, including extraneous data, will be extracted and the model is still able to parse simple tables. Notably, we noticed that for some examples, the quality of the resulting output can change significantly with different temperatures.
Summary
OCR is crucial for extracting structured information from documents. The ability of end-to-end-systems like olmOCR to linearize content gives them a strong advantage over traditional systems. With our fine-tuned version, we can now faithfully extract text including header and footer sections from various documents, which is crucial for business use cases such as invoice parsing. We are curious about how future models will evolve in this fast-paced domain. Special thanks to the Allen Institute for AI for open-sourcing their model, dataset, and code.
If you're curious to try out our finetuned olmOCR-model, we have open-sourced it on HuggingFace .
Models mentioned in this article 2
Datasets mentioned in this article 1
More from this author
How Long Prompts Block Other Requests - Optimizing LLM Performance
Prefill and Decode for Concurrent Requests - Optimizing LLM Performance
Community
Great article, thanks for sharing!
What made you choose the 8xH100 setup for finetuning and how was your experience with it? You did not mention how long training took, so I'm wondering if finetuning olmOCR actually requires that kind of hardware.
Thanks!
Thanks andrei-41!
We chose the 8xH100 setup primarily for speed and convenience, since we had multiple experimental runs. Our final training run lasted 6 hours, so it was definitely overkill. But we rented the cluster via a cloud platform, which was a flexible, low-commitment choice; we could easily spin up/down instances as needed. Also, in terms of GPU memory, less would be definitely sufficient, probably two GPUs are already enough.

Can you share any code on that you used to fine tune this ? I am trying to make an OCR for Handwritten Medical Prescription and not able to get a proper result
- 1 reply
Hi speedbump, we utilized the same training setup that olmOCR used to fine-tune Qwen2-VL-7B: https://github.com/allenai/olmocr/tree/main/olmocr/train
· Sign up or log in to comment
- +7