
Docmatix - A huge dataset for Document Visual Question Answering
- +72


With this blog we are releasing Docmatix - a huge dataset for Document Visual Question Answering (DocVQA) that is 100s of times larger than previously available. Ablations using this dataset for fine-tuning Florence-2 show a 20% increase in performance on DocVQA.

An example from the dataset
We first had the idea to create Docmatix when we developed The Cauldron , an extensive collection of 50 datasets for the fine-tuning of Vision-Language Model (VLM), and Idefics2 in particular. Through this process, we identified a significant gap in the availability of large-scale Document Visual Question Answering (DocVQA) datasets. The primary dataset we relied on for Idefics2 was DocVQA, which contains 10,000 images and 39,000 question-answer (Q/A) pairs. Fine-tuning on this and other datasets, open-sourced models still maintain a large gap in performance to closed-source ones. To address this limitation, we are excited to introduce Docmatix, a DocVQA dataset featuring 2.4 million images and 9.5 million Q/A pairs derived from 1.3 million PDF documents. A 240X increase in scale compared to previous datasets.

Comparing Docmatix to other DocVQA datasets
Here you can explore the dataset yourself and see the type of documents and question-answer pairs contained in Docterix.
Docmatix is generated from PDFA, an extensive OCR dataset containing 2.1 million PDFs . We took the transcriptions from PDFA and employed a Phi-3-small model to generate Q/A pairs. To ensure the dataset's quality, we filtered the generations, discarding 15% of the Q/A pairs identified as hallucinations. To do so, we used regular expressions to detect code and removed answers that contained the keyword “unanswerable”. The dataset contains a row for each PDF. We converted the PDFs to images at a resolution of 150 dpi, and uploaded the processed images to the Hugging Face Hub for easy access. All the original PDFs in Docmatix can be traced back to the original PDFA dataset, providing transparency and reliability. Still, we uploaded the processed images for convenience because converting many PDFs to images can be resource-intensive.
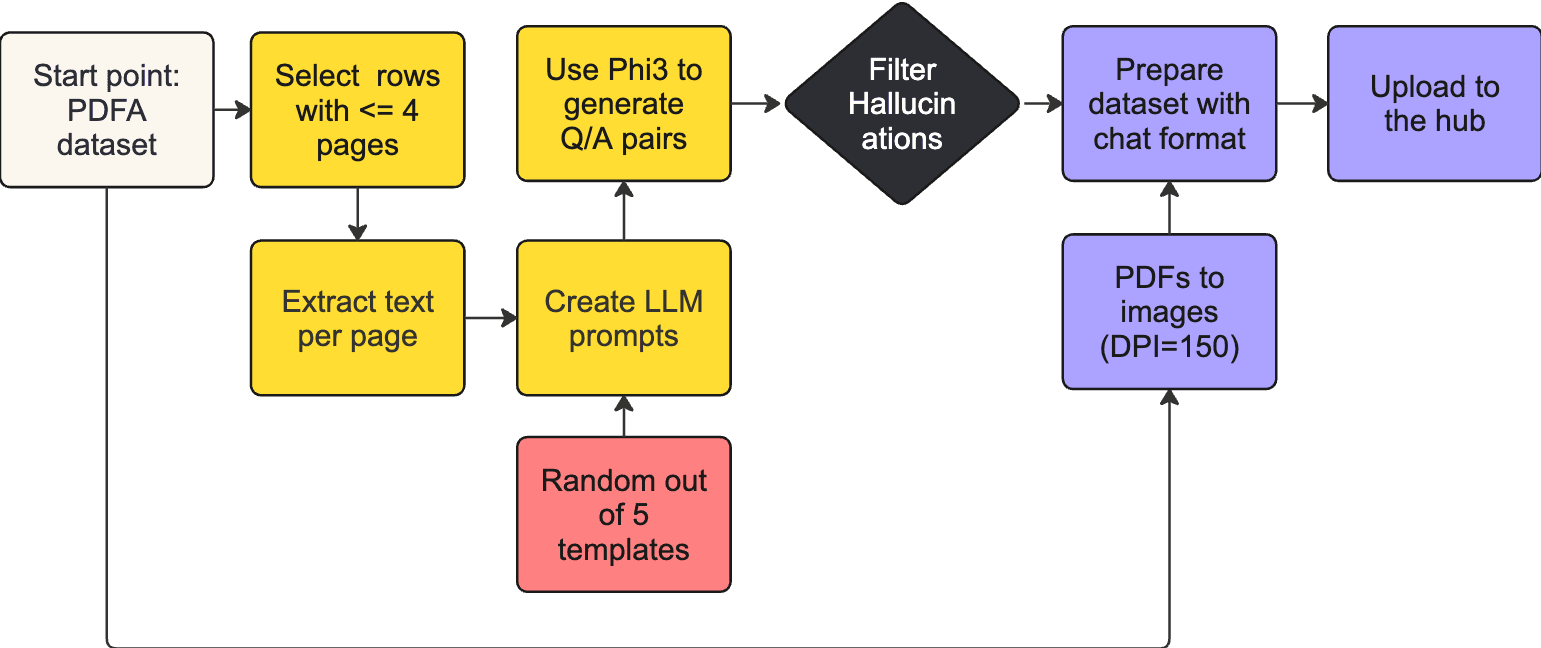
Processing pipeline to generate Docmatix
After processing the first small batch of the dataset, we performed several ablation studies to optimize the prompts. We aimed to generate around four pairs of Q/A per page. Too many pairs indicate a large overlap between them, while too few pairs suggest a lack of detail. Additionally, we aimed for answers to be human-like, avoiding excessively short or long responses. We also prioritized diversity in the questions, ensuring minimal repetition. Interestingly, when we guided the Phi-3 model to ask questions based on the specific information in the document (e.g., "What are the titles of John Doe?"), the questions showed very few repetitions. The following plot presents some key statistics from our analysis:
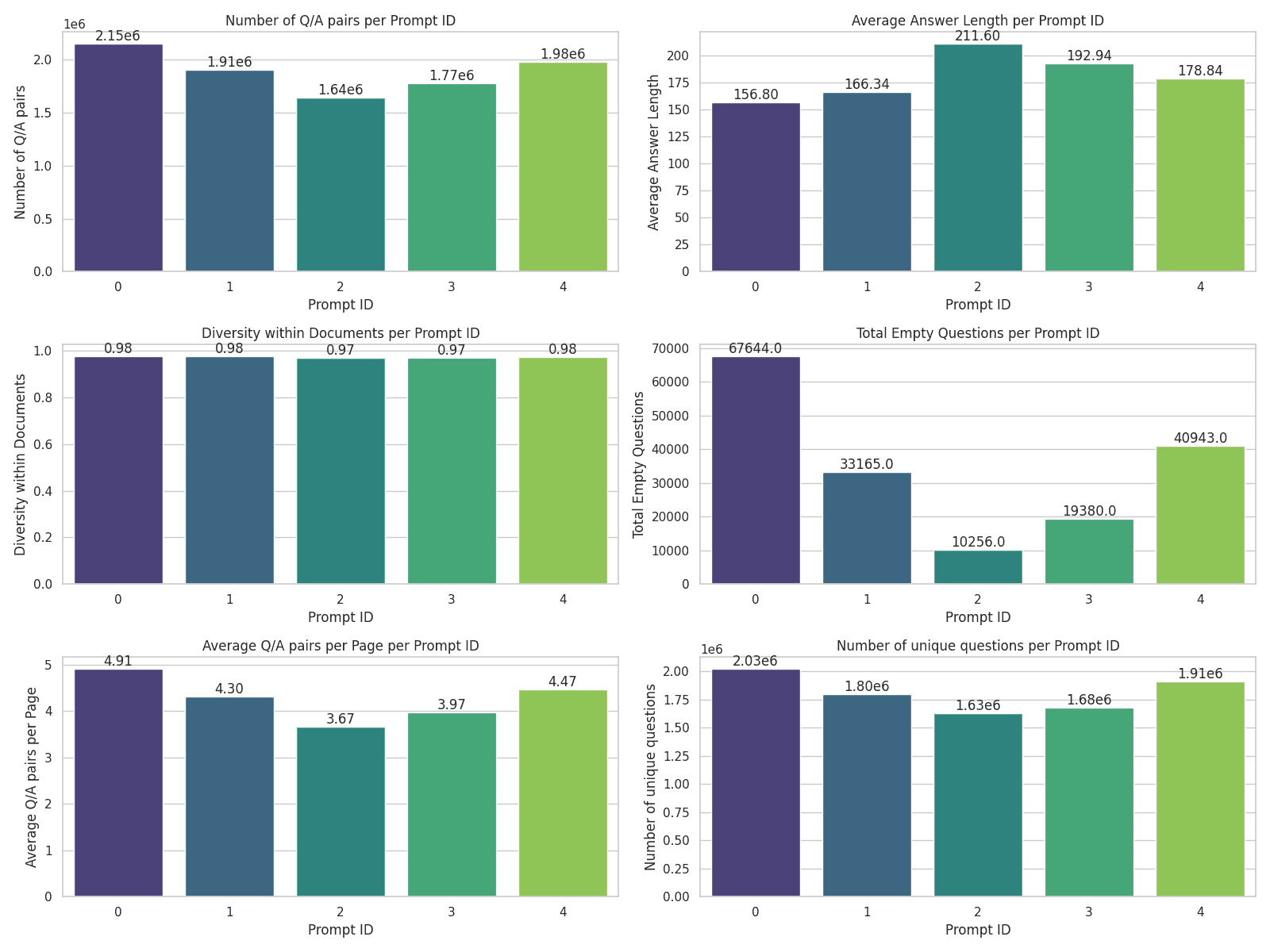
Analysis of Docmatix per prompt
To evaluate Docmatix's performance, we conducted ablation studies using the Florence-2 model. We trained two versions of the model for comparison. The first version was trained over several epochs on the DocVQA dataset. The second version was trained for one epoch on Docmatix (20% of the images and 4% of the Q/A pairs), followed by one epoch on DocVQA to ensure the model produced the correct format for DocVQA evaluation. The results are significant: training on this small portion of Docmatix yielded a relative improvement of almost 20%. Additionally, the 0.7B Florence-2 model performed only 5% worse than the 8B Idefics2 model trained on a mixture of datasets and is significantly larger.
Conclusion
In this post, we presented Docmatix, a gigantic dataset for DocVQA. We showed that using Docmatix we can achieve a 20% increase in DocVQA performance when finetuning Florence-2. This dataset should help bridge the gap between proprietary VLMs and open-sourced VLMs. We encourage the open-source community to leverage Docmatix and train new amazing DocVQA models! We can't wait to see your models on the 🤗 Hub!
Useful Resources
- Docmatix used to finetune Florence-2 Demo
- Finetuning Florence-2 Blog
- Fine tuning Florence-2 Github Repo
- Vision Language Models Explained
We would like to thank merve and leo for their reviews and thumbnails for this blog.
Models mentioned in this article 1
Datasets mentioned in this article 3
More Articles from our Blog
LAVE: Zero-shot VQA Evaluation on Docmatix with LLMs - Do We Still Need Fine-Tuning?
SmolLM - blazingly fast and remarkably powerful
Community
· Sign up or log in to comment
- +66