
Community Evals: Because we're done trusting black-box leaderboards over the community
- +83








TL;DR: Benchmark datasets on Hugging Face can now host leaderboards. Models store their own eval scores. Everything links together. The community can submit results via PR. Verified badges prove that the results can be reproduced.
Evaluation is broken
Let's be real about where we are with evals in 2026. MMLU is saturated above 91%. GSM8K hit 94%+. HumanEval is conquered. Yet some models that ace benchmarks still can't reliably browse the web, write production code, or handle multi-step tasks without hallucinating, based on usage reports. There is a clear gap between benchmark scores and real-world performance.
Furthermore, there is another gap within reported benchmark scores. Multiple sources report different results. From Model Cards, to papers, to evaluation platforms, there is no alignment in reported scores. The result is that the community lacks a single source of truth.
What We're Shipping
Decentralized and transparent evaluation reporting.
We are going to take evaluations on the Hugging Face Hub in a new direction by decentralizing reporting and allowing the entire community to openly report scores for benchmarks. At first, we will start with a shortlist of 4 benchmarks and over time we’ll expand to the most relevant benchmarks.
For Benchmarks: Dataset repos can now register as benchmarks ( MMLU-Pro , GPQA , HLE are already live). They automatically aggregate reported results from across the Hub and display leaderboards in the dataset card. The benchmark defines the eval spec via eval.yaml , based on the Inspect AI format, so anyone can reproduce it. The reported results need to align with the task definition.
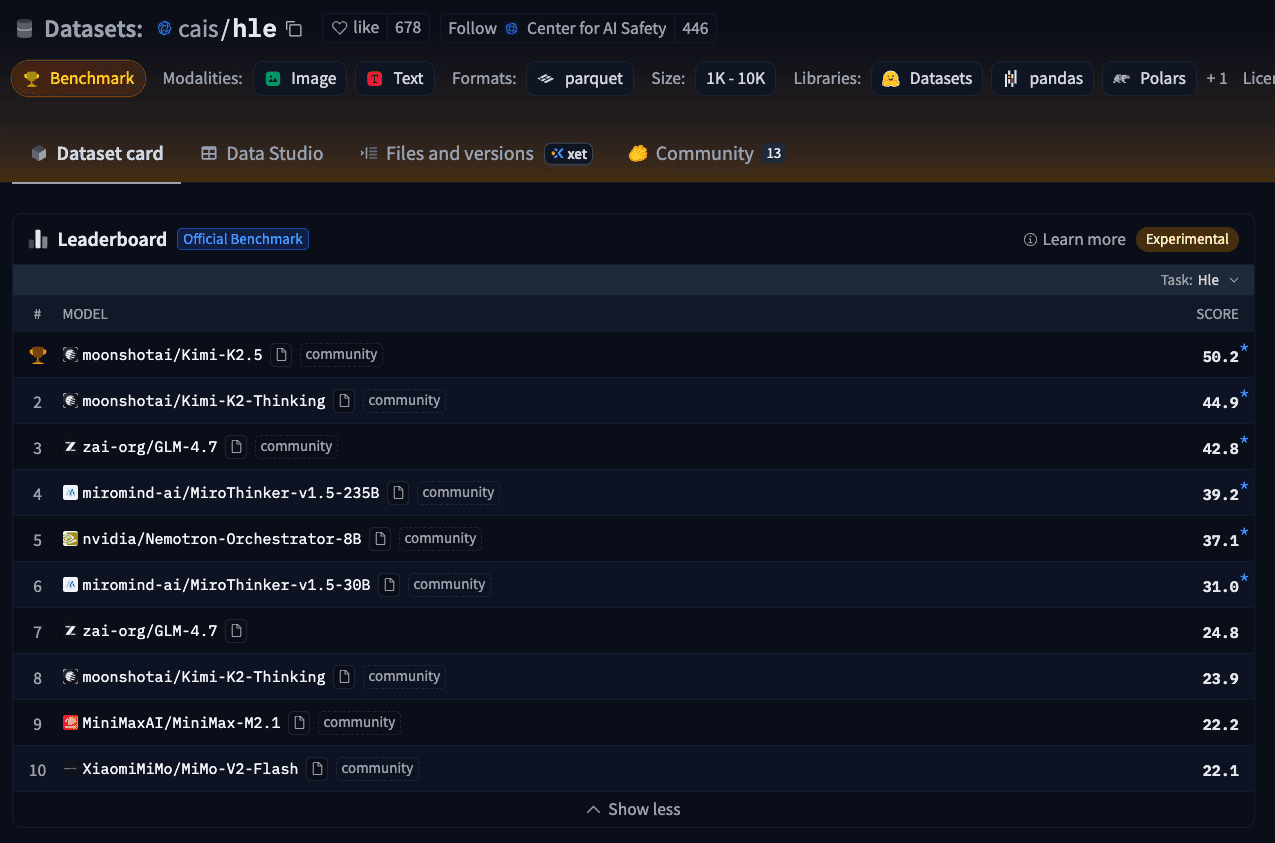
For Models: Eval scores live in .eval_results/*.yaml in the model repo. They appear on the model card and are fed into benchmark datasets. Both the model author’s results and open pull requests for results will be aggregated. Model authors will be able to close score PR and hide results.
For the Community: Any user can submit evaluation results for any model via a PR. Results get shown as "community", without waiting for model authors to merge or close. The community can link to sources like a paper, Model Card, third-party evaluation platform, or inspect eval logs. The community can discuss scores like any PR. Since the Hub is Git based, there is a history of when evals were added, when changes were made, etc. The sources look like below.
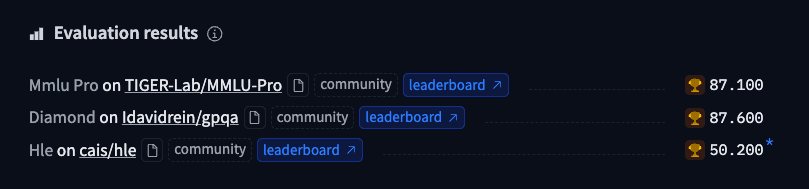
To learn more about evaluation results, check out the docs .
Why This Matters
Decentralizing evaluation will expose scores that already exist across the community in sources like model cards and papers. By exposing these scores, the community can build on top of them to aggregate, track, and understand scores across the field. Also, all scores will be exposed via Hub APIs, making it easy to aggregate and build curated leaderboards, dashboards, etc.
Community evals do not replace benchmarks so leaderboards and closed evals with published results are still crucial. However, we believe it's important to contribute to the field with open eval results based on reproducible eval specs.
This won't solve benchmark saturation or close the benchmark-reality gap. Nor will it stop training on test sets. But it makes the game visible by exposing what is evaluated, how, when, and by whom.
Mostly, we hope to make the Hub an active place to build and share reproducible benchmarks. Particularly focusing on new tasks and domains that challenge SOTA models more.
Get Started
Read the docs: To learn more about evaluation results, check out the docs .
Add eval results: Publish the evals you conducted as YAML files in .eval_results/ on any model repo.
Check out the scores on the benchmark dataset .
Register a new benchmark: Add eval.yaml to your dataset repo and contact us to be included in the shortlist.
The feature is in beta. We're building in the open. Feedback welcome.
Datasets mentioned in this article 3
More Articles from our Blog
Introducing swift-huggingface: The Complete Swift Client for Hugging Face
🇵🇭 FilBench - Can LLMs Understand and Generate Filipino?
- +5
Community

Great initiative, aggregating multiple signals is the way to go!

Although such a measure has not solved the problems encountered in the current evaluation, at least it is indeed a very good measure in terms of decentralization and mobilizing the power of the community for co-construction.

Will there be the integration with existing huggingface lighteval ?
hi @ naufalso ! Lighteval now suport inspect-ai as a backend, so everything supported by inspect is integrrated in lighteval 🔥

Amazing

This is a very important and timely initiative. It’s easy to get lost in the sea of leaderboards, each with its own format and reporting style. The Inspect AI log format brings much‑needed standardization, and having Hugging Face host evaluation logs is a real game changer. One reason many valuable benchmarks fade away is that original contributors often lack the resources to continuously maintain leaderboards. The Community Evals initiative has tremendous potential to address this gap, and I truly appreciate the effort behind it.
We’re hoping to include our planning benchmark, ACPBench , as part of this ecosystem—it's fully compatible with Inspect AI, the evaluation scripts are available on our GitHub.
References
- ACPBench: Reasoning About Action, Change, and Planning, Harsha Kokel, Michael Katz, Kavitha Srinivas, Shirin Sohrabi , AAAI 2025
- ACPBench Hard: Unrestrained Reasoning about Action, Change, and Planning, Harsha Kokel, Michael Katz, Kavitha Srinivas, Shirin Sohrabi , ICLR 2026
· Sign up or log in to comment
- +77