CinePile 2.0 - making stronger datasets with adversarial refinement
- +13



In this blog post we share the journey of releasing CinePile 2.0 , a significantly improved version of our long video QA dataset. The improvements in the new dataset rely on a new approach that we coined adversarial dataset refinement.
We're excited to share both CinePile 2.0 and our adversarial refinement method implementation, which we believe can strengthen many existing datasets and directly be part of future dataset creation pipelines.
If you are mainly interested in the adversarial refinement method, you can jump directly to the Adversarial Refinement section .
Wait. What is CinePile?
In May 2024, we launched CinePile, a long video QA dataset with about 300,000 training samples and 5,000 test samples.
The first release stood out from other datasets in two aspects:
- Question diversity: It covers temporal understanding, plot analysis, character dynamics, setting, and themes.
- Question difficulty: In our benchmark, humans outperformed the best commercial vision models by 25% and open-source ones by 65%.
Taking a look at a data sample
Part of the secret sauce behind it is that it relies on movie clips from YouTube and Q&A distilled from precise audio descriptions designed for visually impaired audiences. These descriptions offer rich context beyond basic visuals (e.g., "What color is the car?"), helping us create more complex questions.

Tell me more. How did you put together the original dataset?
To automate question creation, we first built question templates by inspecting existing datasets like MovieQA and TVQA. We clustered the questions in these datasets using a textual similarity model WhereIsAI/UAE-Large-V1 and then prompted GPT-4 with 10 random examples from each cluster to generate a question template and a prototypical question for each:
Since templates aren't always relevant to every movie clip, we used Gemini 1.0 Pro to select the most appropriate ones for each scene. Next, we feed a language model the scene's text, selected template names (e.g., "Physical Possession"), sample questions, and a system prompt to create scene-specific questions. A well-designed prompt helps the model focus on the entire scene, generating deeper questions while avoiding superficial ones. We found that:
- Providing prototypical examples and including timestamps for dialogues and visual descriptions prevents GPT-4 from hallucinating
- This approach leads to more plausible multiple-choice question (MCQ) distractors
- Asking the model to provide a rationale for its answers improves the quality of the questions
Using this approach, we generate approximately 32 questions per video. Prior to releasing CinePile, we implemented several mechanisms to ensure the quality of the dataset/benchmark that we cover in the next section.
Inspecting the quality of the first results
While our process typically generates well-formed, answerable questions, some turn out to be trivial or rely on basic concepts that don't require watching the clip. To address this, we used several large language models (LLMs) to identify and filter three types of issues:
- Degeneracy Issues A question is considered "degenerate" if its answer is obvious from the question itself (e.g., "What is the color of the pink house?")
- These comprised only a small portion of our dataset
- Since manual review wasn't feasible at our scale, we employed three LLMs—Gemini, GPT-3.5, and Phi-1.5—for automated detection
- Questions were excluded from the evaluation set if all three models answered correctly without any context
Vision Reliance Issues
- Some multiple-choice questions could be answered using dialogue alone, without requiring visual information
- We used the Gemini model to determine if questions could be answered using only dialogue
- Questions received a binary score: 0 if answerable without visuals, 1 if visual information was required
Difficulty Assessment
- To evaluate question difficulty, we tested whether models could answer correctly even when given full context (both visual descriptions and subtitles)
Through continued use of the benchmark by our team and the broader community, we identified several areas for improvement that drove us to consider CinePile 2.0.
CinePile 2.0
For CinePile's second release, we worked together with Hugging Face (following their successful experimentation with fine-tuning Video Llava 7B on CinePile ) to identify and prioritize several areas of improvement.
Issues in CinePile 1.0
While the degeneracy filtering was useful in CinePile 1.0, it had several limitations:
- Some questions could be answered using just the Q&A pairs, without requiring transcripts or visual content
- Many flagged questions contained valuable insights from the video - rather than discarding them, they could have been rephrased to better capture their value
- Degeneracy checks were limited to the test set: running multiple models—especially proprietary ones—was too expensive at scale for CinePile 1.0's training set
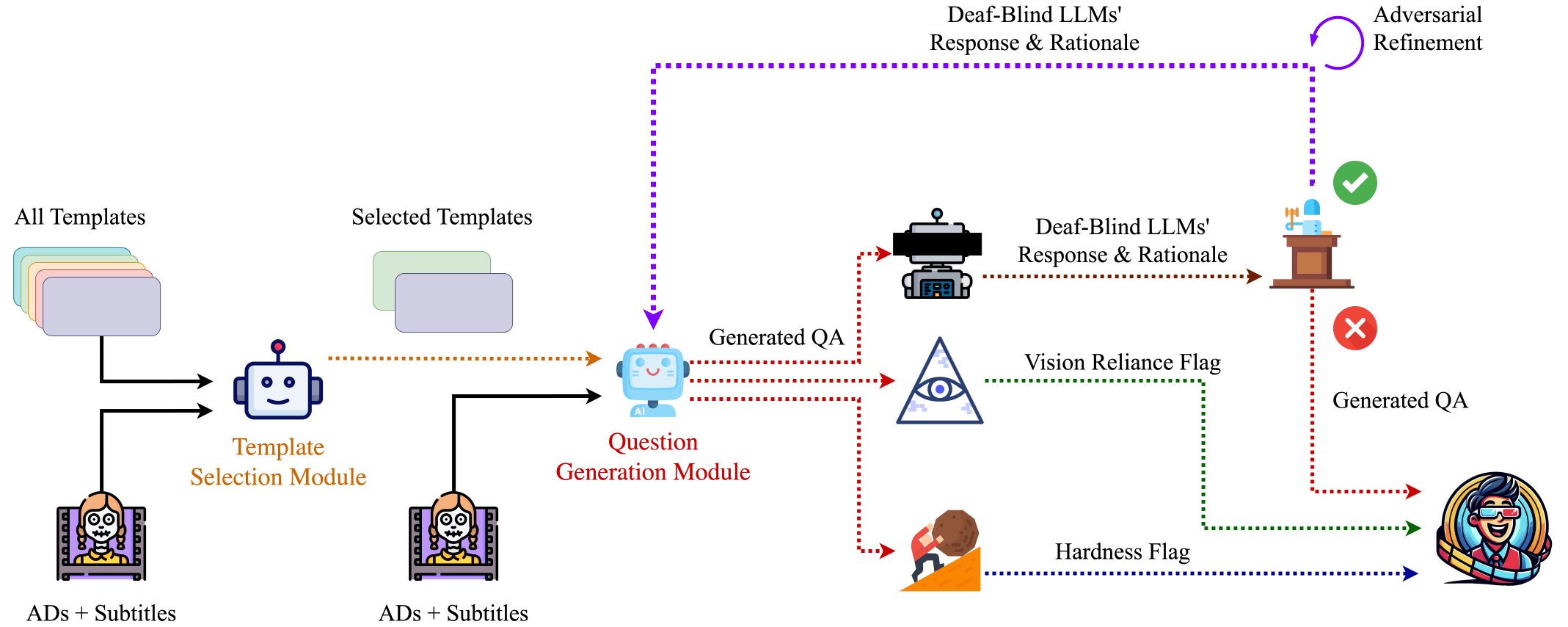
To address these issues, we introduced a new Adversarial Refinement pipeline that helps improve weak questions rather than simply discarding them. This approach can be more easily applied at scale. Throughout this post, we'll refer to the model(s) that identify degenerate questions (using only the question and answer choices, without visual or dialogue information) as the "Deaf-Blind LLM."
Adversarial Refinement
The Adversarial Refinement pipeline aims to modify questions or answers until a Deaf-Blind LLM cannot easily predict the correct answer. Here's how it works:
- The Deaf-Blind LLM provides both an answer and a rationale explaining its choice based solely on the question
- These rationales help identify implicit cues or biases embedded in the question
- Our question-generation model uses this rationale to modify the question and/or answer choices, removing implicit clues
- This process repeats up to five times per question until the Deaf-Blind LLM's performance drops to random chance
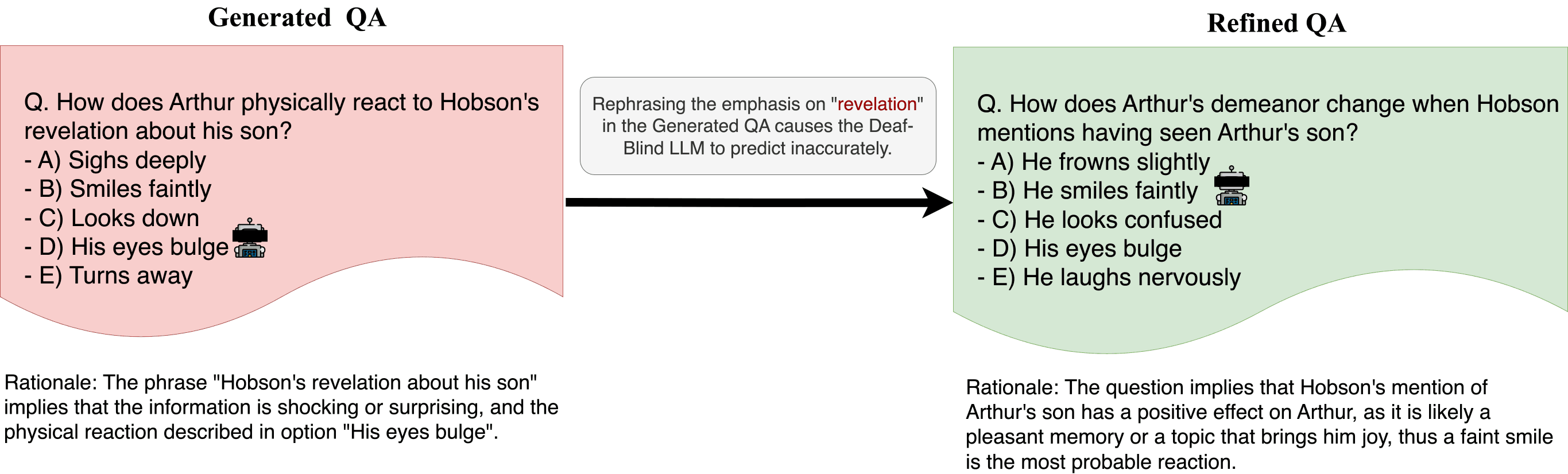
Given the computational demands of this iterative process, we needed a powerful yet accessible LLM that could run locally to avoid API usage limits, delays, and cloud service costs. We chose:
- LLaMA 3.1 70B (open-source model) as the Deaf-Blind LLM
- GPT-4 for question modification generation
To account for random chance, we:
- Tested all five permutations of answer choice order
- Marked a question as degenerate if the model answered correctly in three out of five attempts
Results of the adversarial refinement
Briefly, this was the impact of running adversarial refinement in CinePile:
- Successfully modified 90.24% of degenerate Q&A pairs in the test set
- Manually reviewed unfixable Q&A pairs (~80 out of 800) Modified when possible
- Otherwise excluded from evaluation split
- Retained unfixable ones as they don't negatively impact performance
Implementation
In this release, we're publishing both our adversarial refinement pipeline and the code for identifying weak questions. The complete implementation, including all prompts, is available in our public repository .
Evaluations
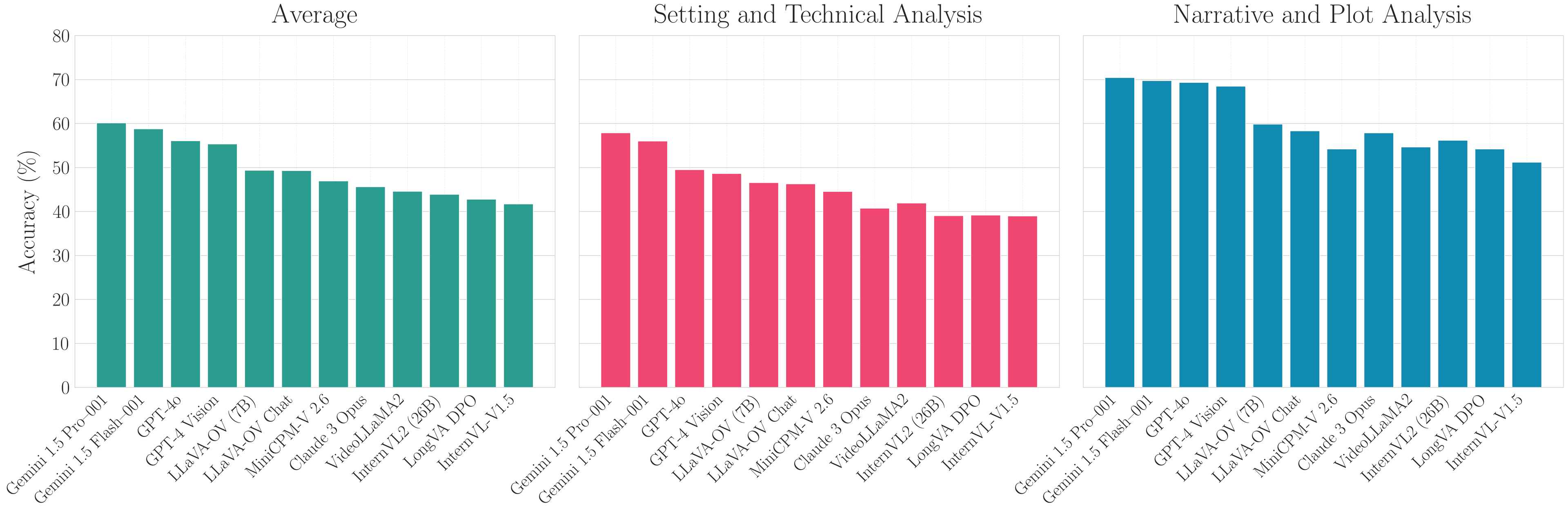
After testing both previously evaluated models and 16 new Video-LLMs on the modified test set, we’ve highlighted the top performers in the figure below. Here’s what the results show:
- Gemini 1.5 Pro led among commercial Vision Language Models (VLMs) Excelled particularly in "Setting and Technical Analysis"
- Best performance on visually-driven questions about movie environments and character interactions
GPT-based models showed competitive performance
- Strong in "Narrative and Plot Analysis"
- Performed well on questions about storylines and character interactions
Gemini 1.5 Flash , a lighter version of Gemini 1.5 Pro
- Achieved 58.75% overall accuracy
- Performed particularly well in "Setting and Technical Analysis"
Open Source models
The open-source video-LLM community has made significant progress from the first to the current release of CinePile. This is what we learned:
- LLaVa-One Vision leads open-source models Achieved 49.34% accuracy
- A dramatic improvement from CinePile 1.0's best performer (Video LLaVA at 22.51%)
Smaller models showed competitive performance
- LLaVa-OV (7B parameters)
- MiniCPM-V 2.6 (8B parameters)
- Both outperformed InternVL2 (26B parameters)
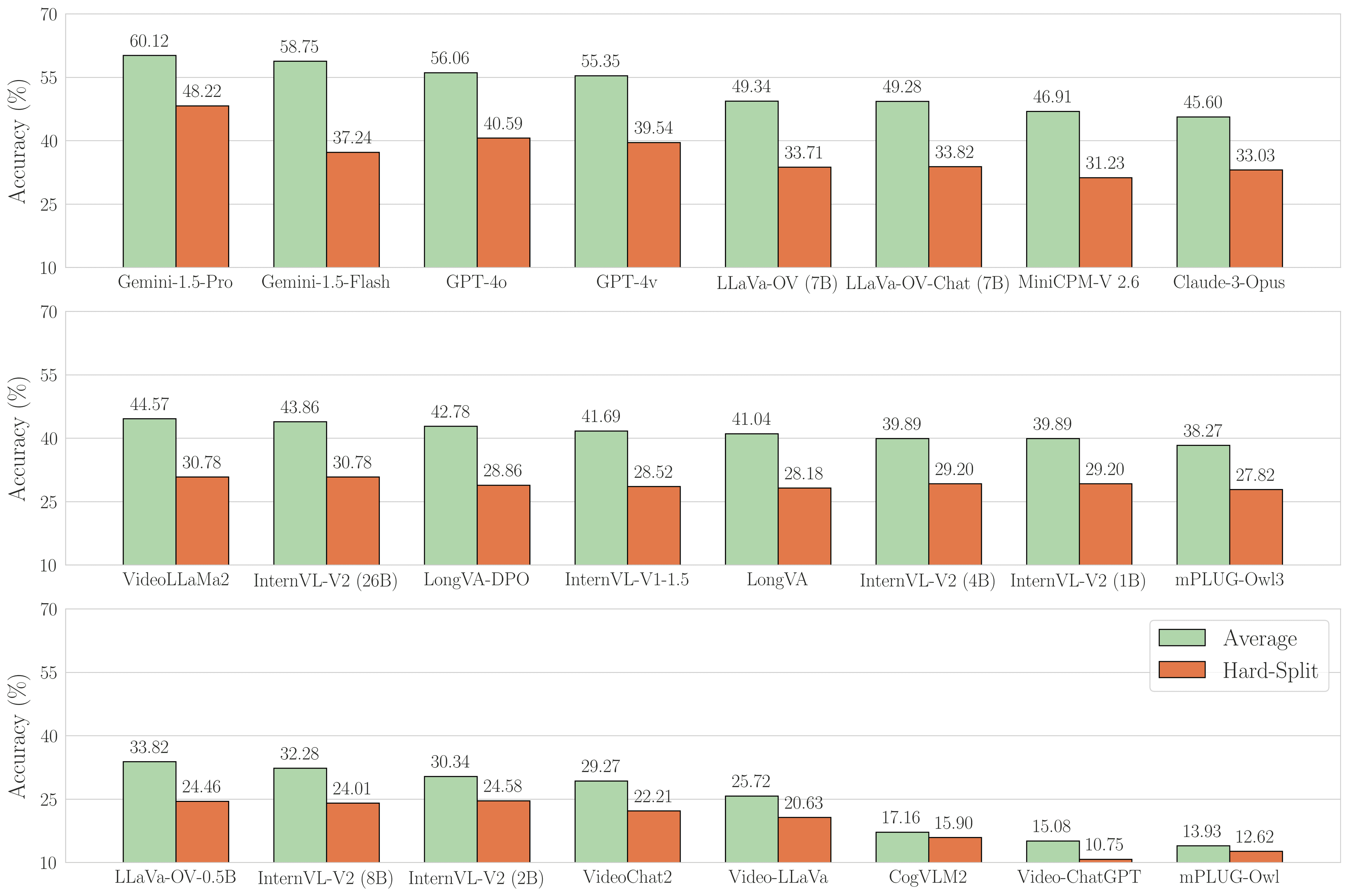
There is room to improve
- Nearly all models showed 15-20% accuracy drop on the hard-split
- Indicates significant room for improvement
Hard Split
The hard-split results in CinePile clearly demonstrate that current models still lag far behind human capability in understanding visual narratives and story elements. This gap highlights the value of CinePile's new release as a benchmark for measuring progress toward more sophisticated visual understanding.
Leaderboard
We've launched a new CinePile Leaderboard that will be continuously updated as new models emerge. Visit the space to learn how to submit your own models for evaluation.
Models mentioned in this article 2
Datasets mentioned in this article 1
More Articles from our Blog
TimeScope: How Long Can Your Video Large Multimodal Model Go?
FineVideo: behind the scenes
- +2
Community
· Sign up or log in to comment
- +7